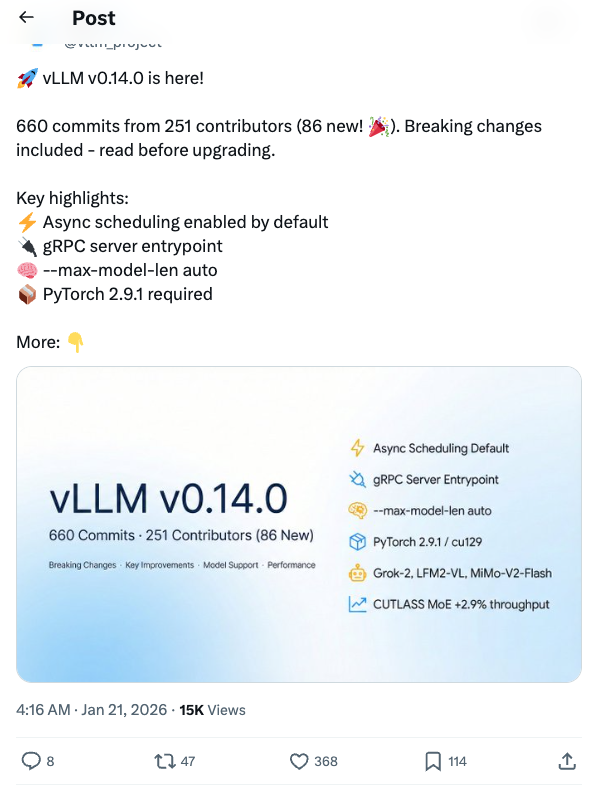
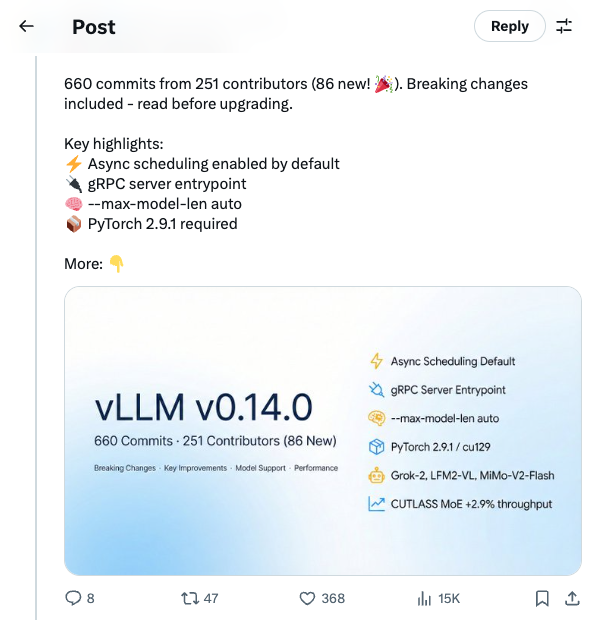
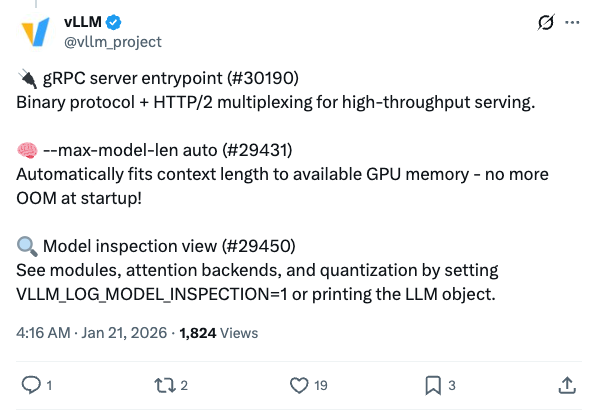
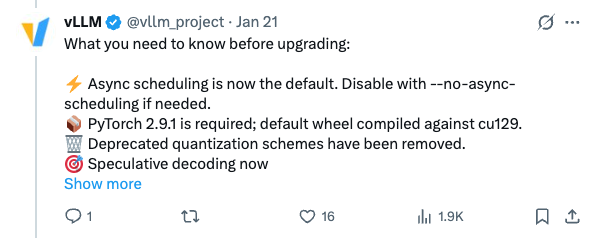
🧵 vLLM v0.14.0 is here! 660 commits from 251 contributors (86 new! ). Breaking changes included - read before upgrading. Key highlights: Async scheduling enabled by default gRPC server entrypoint --max-model-len auto PyTorch 2.9.1 required More: 🧵 What you need to know before upgrading: Async scheduling is now the default. Disable with --no-async-scheduling if needed. PyTorch 2.9.1 is required; default wheel compiled against cu129. Deprecated quantization schemes have been removed. Speculative decoding now fails on unsupported sampling parameters instead of silently ignoring them. 🧵 gRPC server entrypoint (#30190) Binary protocol + HTTP/2 multiplexing for high-throughput serving. --max-model-len auto (#29431) Automatically fits context length to available GPU memory - no more OOM at startup! Model inspection view (#29450) See modules, attention backends, and quantization by setting VLLM_LOG_MODEL_INSPECTION=1 or printing the LLM object. 🧵 New Model Support: Grok-2 with tiktoken tokenizer LFM2-VL vision-language model MiMo-V2-Flash GLM-ASR audio K-EXAONE-236B-A23B MoE LoRA now supports multimodal tower/connector for LLaVA, BLIP2, PaliGemma, Pixtral, and more 🧵 CUTLASS MoE optimizations: 2.9% throughput + 10.8% TTFT improvement via fill(0) optimization Hardware updates: SM103 support B300 Blackwell MoE configs Marlin for Turing (sm75) Large-scale serving: XBO (Extended Dual-Batch Overlap), NIXL asymmetric TP
Thread Screenshots
Images
