Academic Tweets
2410 tweets🧵 I have 4 papers accepted at ICLR! Super excited about this milestone, and congrats to all collaborators! Quick thread with links 🧵 1) MindCube Can VLMs imagine full 3D space from limited views, like humans? We introduce MindCube (21k+ Qs / 3k+ images) to test: • cognitive mapping • perspective-taking • mental simulation (what-if movement) Result: current strong VLMs are close to chance here But a simple scaffold works: map-then-reason Explicitly generate a cognitive map → reason on it Accuracy 37.8 → 60.8 (+23.0) RL → 70.7 (+32.9) Takeaway: structured spatial representations + reasoning is key https:// x.com/ManlingLi_/sta tus/1939760677133987952?s=20 … 🧵 2) Active Spatial Belief Most spatial benchmarks are still passive QA: given an observation, answer a question They don’t disentangle: (1) can a model actively build/update spatial belief under uncertainty (2) is its spatial reasoning consistent given offline, passive observations So we propose ToS = Theory of Mind, but for space: can the model explore to reduce uncertainty and maintain a consistent internal map? We benchmark both text and visual environments, with curiosity-driven exploration (not task solving) to complete an internal map We also separate exploration vs reasoning (via scripted proxy agents’ logs), revealing clear failure modes (egomotion errors, global inconsistency, etc.) https:// openreview.net/forum?id=8iPwq r6Adk … 🧵 3) LM Personality Subnetworks Are personas injected by prompts/RAG/finetuning Or already inside model parameters? We find persona-specialized subnetworks already inside LLMs Identify activation signatures with a tiny calibration set → mask & isolate Training-free, no parameter updates These subnetworks align better than external-knowledge baselines, and more efficiently We also study opposing personas (introvert vs extrovert) with contrastive pruning Takeaway: persona tendencies are often embedded in parameters 🧵 4) Interactive Weak-to-Strong w/ Failure Trajectories Weak-to-strong beyond classification → interactive decision-making Key idea: don’t just learn weak model’s successes Learn from its failures too (failure trajectories are informative) We build trajectory trees + combine with MCTS for efficient optimization We also give a formal guarantee for why failure supervision helps W2S Big gains across domains in reasoning + decision-making, scalable setup


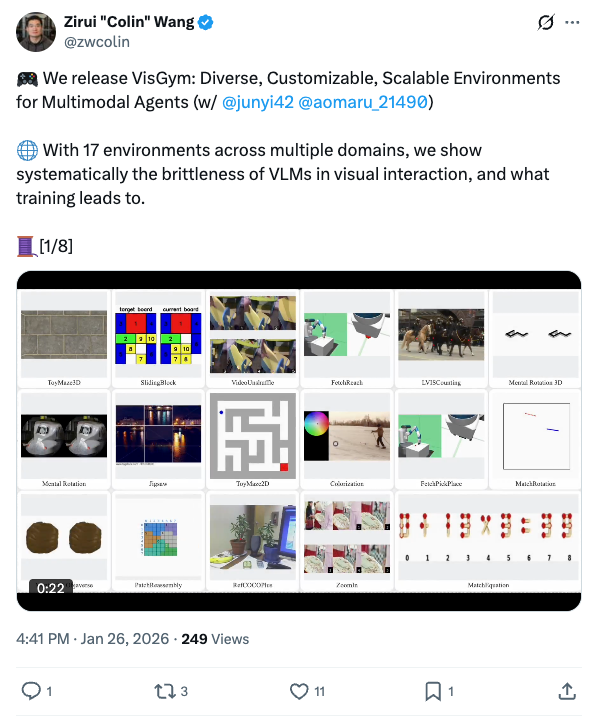
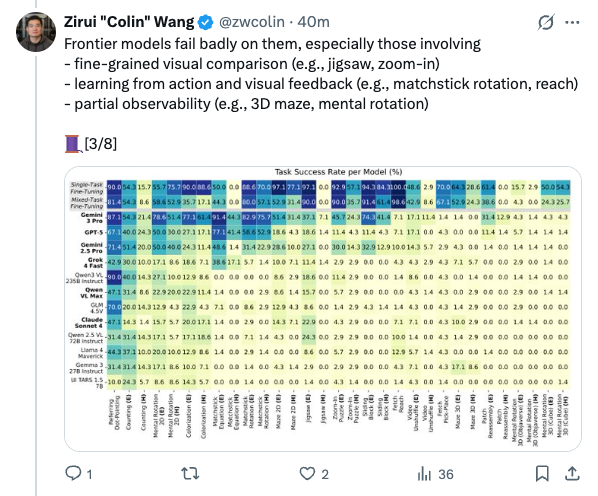
🧵 We release VisGym: Diverse, Customizable, Scalable Environments for Multimodal Agents (w/ @junyi42 @aomaru_21490 ) With 17 environments across multiple domains, we show systematically the brittleness of VLMs in visual interaction, and what training leads to. [1/8] 🧵 Despite rapid progress in visual reasoning with VLMs and success in domain-specific settings like computer-using agents and robotics, we are still overlooking a universal agentic capability: visual interaction. We did the heavy lifting to systematically stress-test it. [2/8] 🧵 Frontier models fail badly on them, especially those involving - fine-grained visual comparison (e.g., jigsaw, zoom-in) - learning from action and visual feedback (e.g., matchstick rotation, reach) - partial observability (e.g., 3D maze, mental rotation) [3/8] 🧵 We find that models frequently - get stuck repeating actions - ignore information from past interactions - terminate episodes without reaching the goal - ignore visual changes in the scene [4/8] 🧵 When designing visual interaction workflows, we find that - unbounded history can hurt performance - text-based task representations often outperform visual ones - adding text feedback to visual feedback helps - providing the final goal image does not always help [5/8] 🧵 In supervised finetuning, we find that - generalization is task-specific, and stronger base models generalize better - both the visual encoder and the LLM need finetuning for visual interaction - teaching models to explore matters more than more oracle trajectories [6/8] 🧵 We hope VisGym can serve as a foundation for measuring and improving visual interaction capabilities in vision language models. Website: http:// visgym.github.io Paper: http:// arxiv.org/abs/2601.16973 Code: http:// github.com/visgym/visgym [7/8] 🧵 Grateful to our incredible collaborators and faculty advisors: @LongTonyLian @letian_fu @lisabdunlap @Ken_Goldberg @XDWang101 @istoica05 @_dmchan @sewon__min @profjoeyg . Special thanks to @OpenRouterAI and @vesslai for their support in evaluation and training. [8/8]

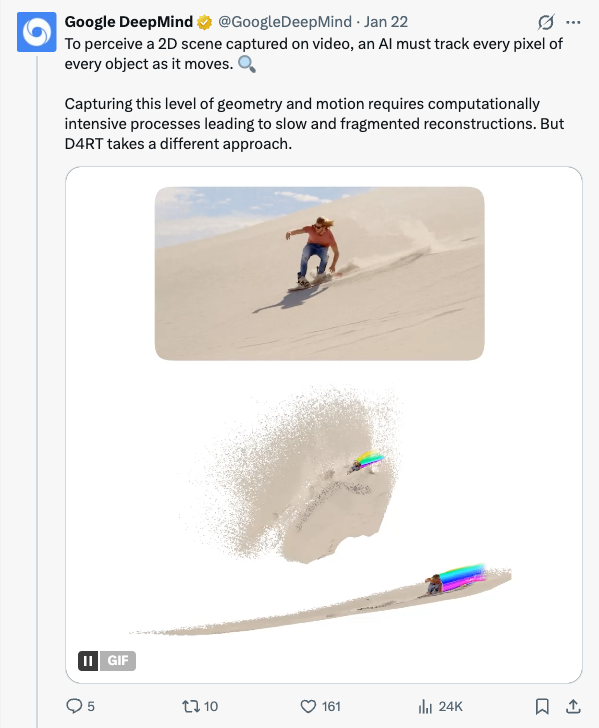
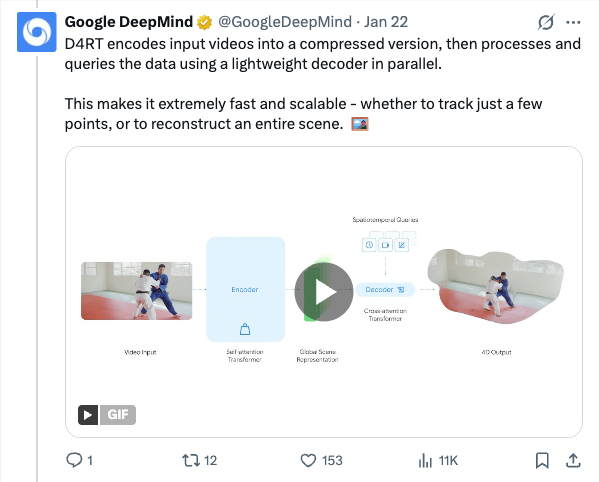
🧵 We're helping AI to see the 3D world in motion as humans do. Enter D4RT: a unified model that turns video into 4D representations faster than previous methods - enabling it to understand space and time. This is how it works 🧵 To perceive a 2D scene captured on video, an AI must track every pixel of every object as it moves. Capturing this level of geometry and motion requires computationally intensive processes leading to slow and fragmented reconstructions. But D4RT takes a different approach. 🧵 D4RT encodes input videos into a compressed version, then processes and queries the data using a lightweight decoder in parallel. This makes it extremely fast and scalable - whether to track just a few points, or to reconstruct an entire scene. 🧵 Many 4D tasks can now be solved with one model, enabling us to: Predict a pixel’s 3D trajectory by looking for its location across different time steps. Freeze time and the camera viewpoint to generate a scene's complete 3D structure. 🧵 D4RT can even create and align 3D snapshots of a single moment from different viewpoints - easily recovering the camera's trajectory. 🧵 4D reconstruction often fails on dynamic objects, resulting in ghosting artifacts or processing lag. D4RT can continuously understand what's moving while running 18x–300x faster than previous methods - processing a 1-minute video in roughly 5 seconds on a single TPU chip. 🧵 We believe this research could have unlimited applications in the real-world. From providing spatial awareness in robotics , leveling up efficiency in AR , and expanding the capabilities in world models D4RT’s potential is a necessary step on the path towards AGI. Find out more → https:// goo.gle/introducing-d4 rt …

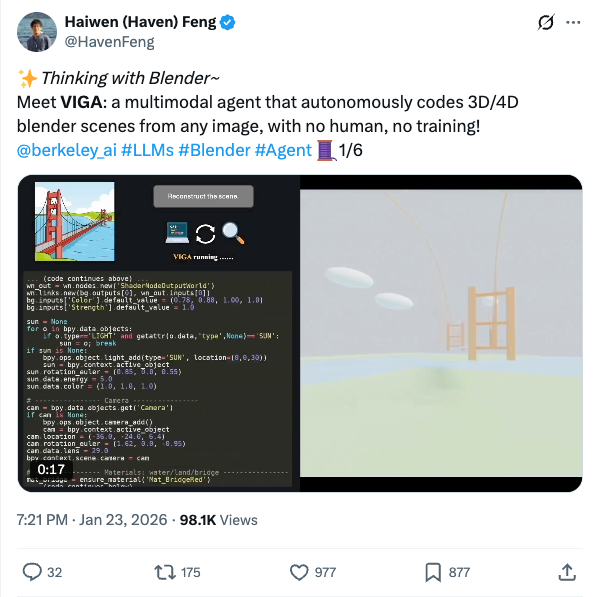
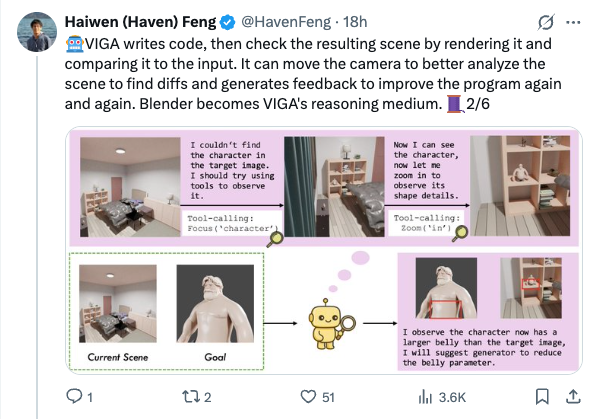
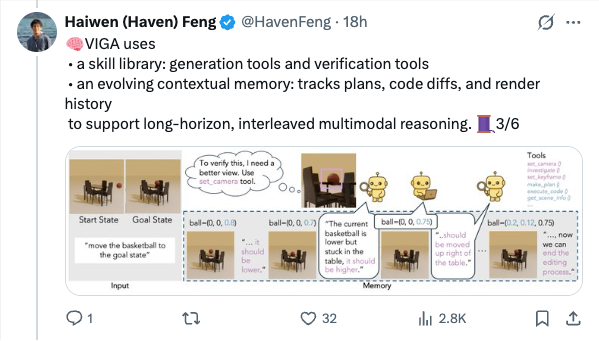
🧵 Thinking with Blender~ Meet VIGA: a multimodal agent that autonomously codes 3D/4D blender scenes from any image, with no human, no training! @berkeley_ai #LLMs #Blender #Agent 1/6 🧵 VIGA writes code, then check the resulting scene by rendering it and comparing it to the input. It can move the camera to better analyze the scene to find diffs and generates feedback to improve the program again and again. Blender becomes VIGA's reasoning medium. 2/6 🧵 VIGA uses • a skill library: generation tools and verification tools • an evolving contextual memory: tracks plans, code diffs, and render history to support long-horizon, interleaved multimodal reasoning. 3/6 🧵 VIGA goes beyond 3D reconstruction: It can edit 3D scenes, add 4D interaction and even edit Powerpoint! Empirically: +32.65% on BlenderGym, +117.17% on SlideBench. 4/6 🧵 We also release BlenderBench: a harder benchmark for agentic inverse graphics. It stress tests fine-level camera control, multi-step edits, compositional changes. On its hardest task, VIGA achieves a +512% gain! 5/6 🧵 Paper + project: https:// arxiv.org/abs/2601.11109 https:// fugtemypt123.github.io/VIGA-website/ Code: https:// github.com/Fugtemypt123/V IGA-release … Benchmark: https:// huggingface.co/datasets/DietC oke4671/BlenderBench … This is an amazing collaboration with @shaofeng_y27736 , @aomaru_21490 , @ZhiruoW , @xiuyu_l , @Michael_J_Black , @trevordarrell , @akanazawa . 6/6
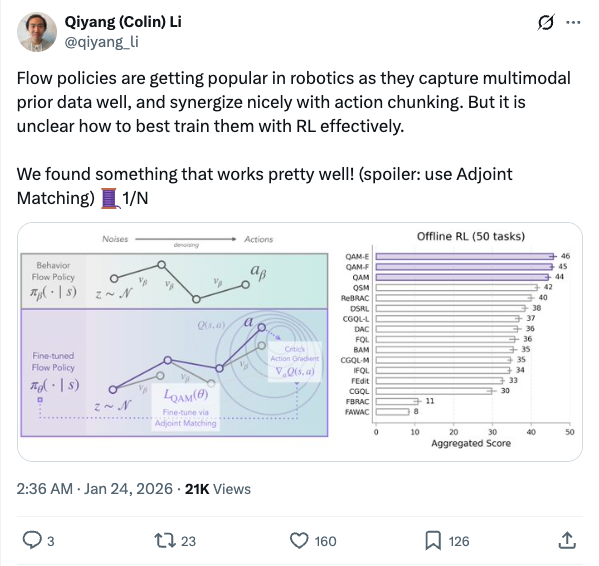
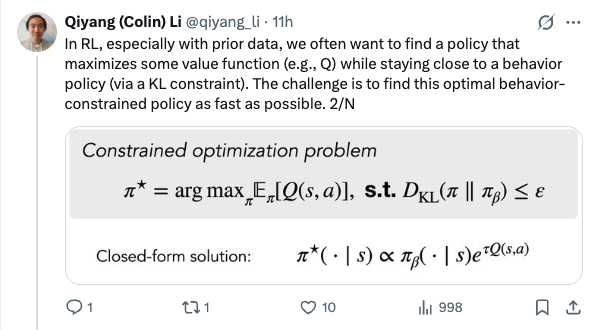
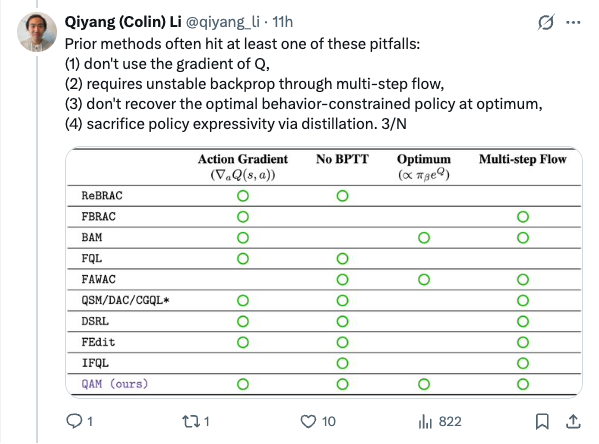
🧵 Flow policies are getting popular in robotics as they capture multimodal prior data well, and synergize nicely with action chunking. But it is unclear how to best train them with RL effectively. We found something that works pretty well! (spoiler: use Adjoint Matching) 1/N 🧵 In RL, especially with prior data, we often want to find a policy that maximizes some value function (e.g., Q) while staying close to a behavior policy (via a KL constraint). The challenge is to find this optimal behavior-constrained policy as fast as possible. 2/N 🧵 Prior methods often hit at least one of these pitfalls: (1) don't use the gradient of Q, (2) requires unstable backprop through multi-step flow, (3) don't recover the optimal behavior-constrained policy at optimum, (4) sacrifice policy expressivity via distillation. 3/N 🧵 It turns out that Adjoint Matching, a recently proposed technique from the flow-matching generative modeling literature is perfectly suited for solving these issues all at once in RL! How does Adjoint Matching work? Let's dive in! 4/N 🧵 Actions from a flow policy are generated by integrating Gaussian noises through an ODE. We can construct an SDE that results in the same marginal distribution and use this SDE to reformulate the constrained optimization problem above as a stochastic optimal control objective! 5/N 🧵 Solving this new objective seemingly requires us to backprop through an SDE, causing potential instability issues. In Adjoint Matching, Domingo-Enrich et al., use a reverse ODE to construct an objective with the same optimum but without direct backprop! 6/N 🧵 Applying this to RL yields our algorithm QAM. It avoids all prior issues: we use the action gradient from Q to directly fine-tune a flow policy towards the optimal behavior-constrained policy without using unstable backprop or sacrificing policy expressivity. 7/N 🧵 In practice, we also find that it is often beneficial to relax the KL constraint such that the fine-tuned policy can output actions that are close "geometrically" close to the behavior actions in the prior data but have low probability under the behavior distribution. 8/N 🧵 We experiment with two variants. The first variant trains a FQL policy on top of QAM's fine-tuned policy. The second variant trains a residual policy to refine the action samples from QAM's fine-tuned policy. We call these two QAM-F and QAM-E (E for edit) respectively. 9/N 🧵 We evaluated QAM on OGBench, a popular offline RL benchmark with a diverse set of long-horizon challenging tasks ranging from locomotion to manipulation. All three variants of QAM exhibit strong performance. 10/N 🧵 We also find the QAM-E variant is particularly well-suited for online fine-tuning. On some of the hardest domains from the benchmark, our method exhibits strong sample-efficiency and robustness across the board. 11/N 🧵 That is all! This project has been a fun journey in searching for a flow + RL method that brings the best of prior methods. And it would not be possible without my amazing advisor @svlevine !! Code+exp data: http:// github.com/colinqiyangli/ qam … Paper: https:// arxiv.org/abs/2601.14234 12/N=12
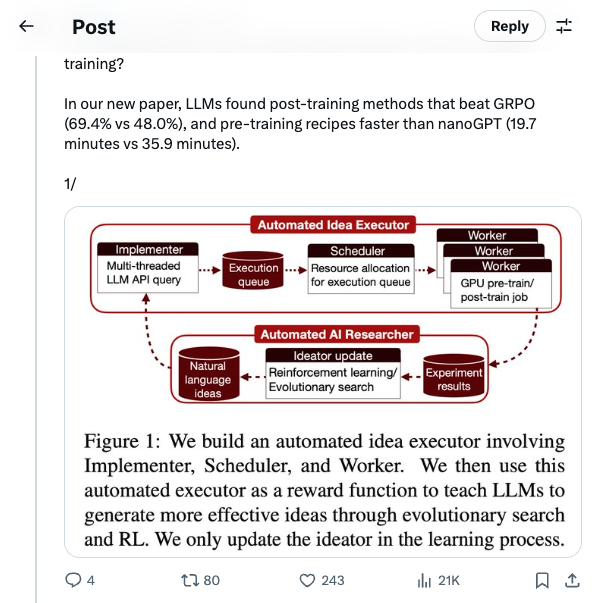
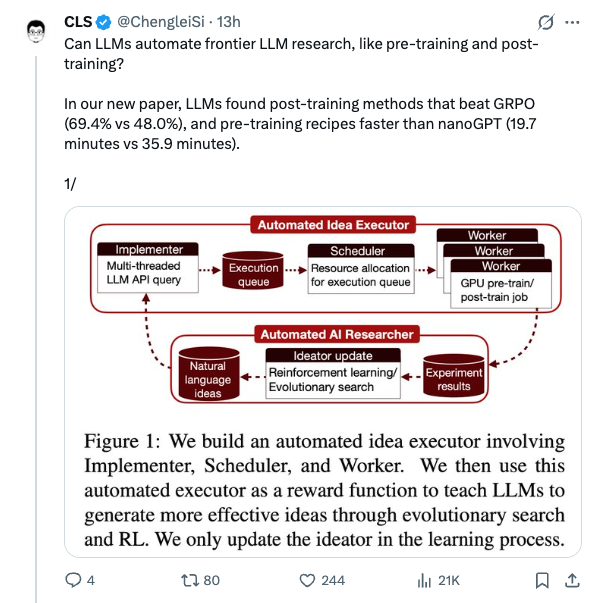
🧵 Can LLMs automate frontier LLM research, like pre-training and post-training? In our new paper, LLMs found post-training methods that beat GRPO (69.4% vs 48.0%), and pre-training recipes faster than nanoGPT (19.7 minutes vs 35.9 minutes). 1/ 🧵 Paper: https:// arxiv.org/abs/2601.14525 To make the scope clear, our automated AI researchers aren’t just tuning hyper-parameters; they are often experimenting with meaningful algorithmic ideas shown below. 2/ 🧵 How did we achieve this? We first build an automated executor to implement ideas and launch large-scale parallel GPU experiments to verify their effectiveness. Then we use the execution reward for evolutionary search and RL. 3/ 🧵 Execution-guided evolutionary search is sample-efficient: it finds methods that significantly outperform the GRPO baseline on post-training, and pre-training recipes that significantly outperform the nanoGPT baseline, all within just ten search epochs. 4/ 🧵 It’s much more effective than just sampling more ideas and doing best-of-N. But models tend to saturate early, and only Claude-4.5-Opus exhibits clear scaling trends. 5/ 🧵 RL from execution reward can successfully improve the average reward, but does not improve the max reward :( The reason is: models are converging on a few easy-to-implement ideas and are avoiding ideas that are difficult to execute (which will get them 0 reward). 6/ 🧵 Read the full paper for many more experiment details, analyses, examples, and our thoughts on future directions. Big thanks to my wonderful co-lead @ZitongYang0 , and our advisors @YejinChoinka @EmmanuelCandes @Diyi_Yang @tatsu_hashimoto for making this project happen. 7/ 🧵 Shout out to @tydsh @edwardfhughes @lschmidt3 @cong_ml @jennyzhangzt @jiaxinwen22 @ChrisRytting @zhouandy_ @xinranz3 @StevenyzZhang @ShichengGLiu @henryzhao4321 @jyangballin @WilliamBarrHeld @haotian_yeee @LukeBailey181 and many others for the helpful discussion. 8/ 🧵 Last but not least, we thank @LaudeInstitute , @thinkymachines , and DST Global for their generous sponsorship of compute resources. 9/9

🧵 New preprint: "LLM-in-Sandbox Elicits General Agentic Intelligence" TL;DR: Giving LLMs access to a code sandbox unlocks emergent capabilities for non-code tasks. https:// arxiv.org/abs/2601.16206 https:// huggingface.co/papers/2601.16 206 … https:// llm-in-sandbox.github.io https:// github.com/llm-in-sandbox /llm-in-sandbox … 🧵 Contributions: LLMs spontaneously exploit sandbox capabilities (external access, file I/O, code execution) without training RL with non-agentic data enables agentic generalization Efficient deployment: up to 8× token savings Feedback welcome!


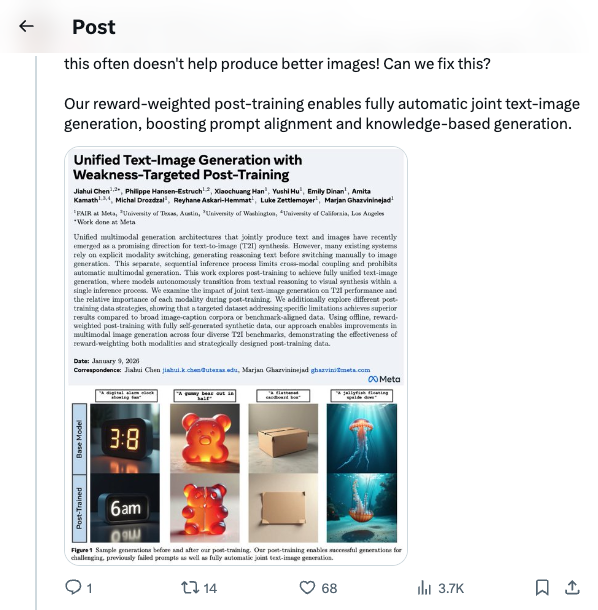
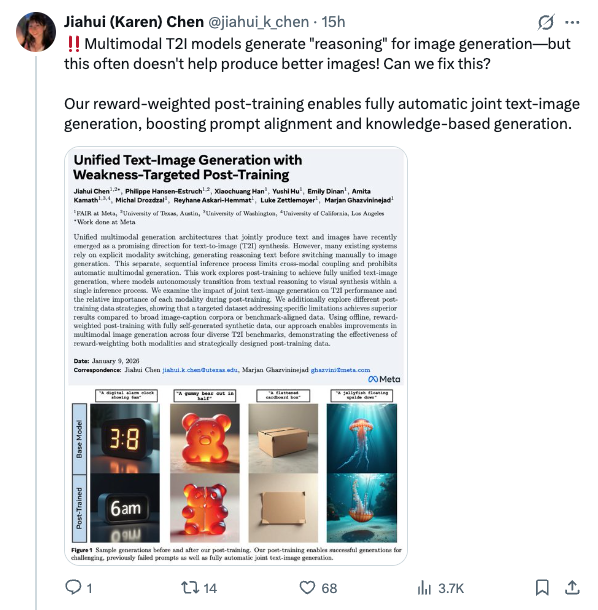
🧵 Multimodal T2I models generate "reasoning" for image generation—but this often doesn't help produce better images! Can we fix this? Our reward-weighted post-training enables fully automatic joint text-image generation, boosting prompt alignment and knowledge-based generation. 🧵 Key findings: → VQAScore (an eval metric) + Qwen2.5-VL is a better reward than existing T2I reward models → For training data, weakness-targeted prompts beat both general image captions and benchmark-specific prompts → Reward-weighting both modalities jointly is best 2/n 🧵 Results on 4 diverse benchmarks and full details in the paper: https:// arxiv.org/abs/2601.04339 This work was done at @AIatMeta . Thanks to my collaborators @tokenpilled65B @XiaochuangHan @huyushi98 @em_dinan @kamath_amita @michal_drozdzal @ReyhaneAskari @LukeZettlemoyer @gh_marjan 3/n

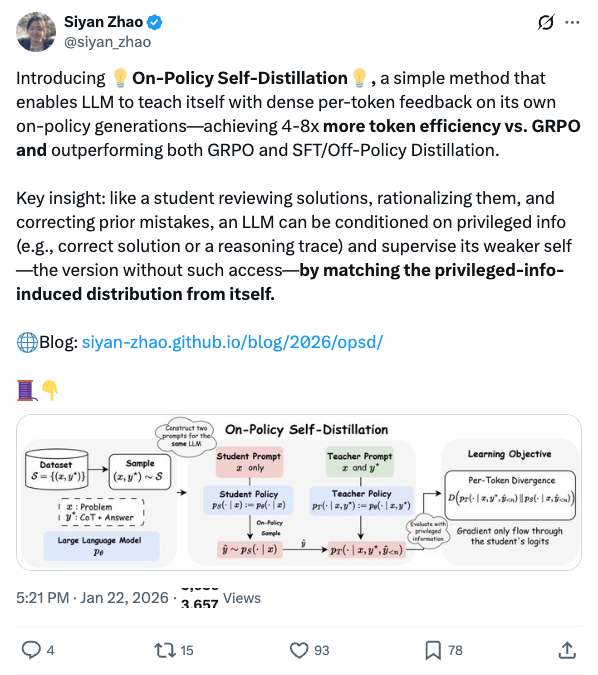
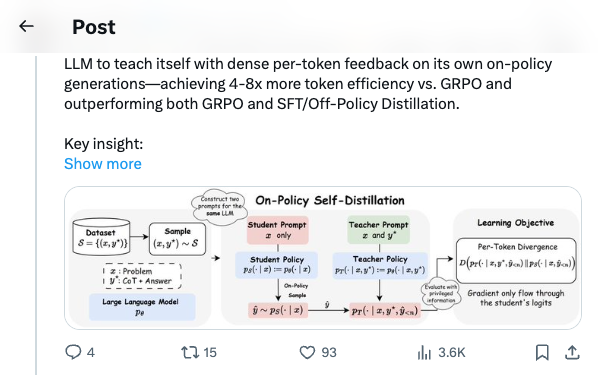
🧵 Introducing On-Policy Self-Distillation, a simple method that enables LLM to teach itself with dense per-token feedback on its own on-policy generations—achieving 4-8x more token efficiency vs. GRPO and outperforming both GRPO and SFT/Off-Policy Distillation. Key insight: like a student reviewing solutions, rationalizing them, and correcting prior mistakes, an LLM can be conditioned on privileged info (e.g., correct solution or a reasoning trace) and supervise its weaker self—the version without such access—by matching the privileged-info-induced distribution from itself. Blog: https:// siyan-zhao.github.io/blog/2026/opsd/ 🧵 2/n As compared to SFT/off-policy distillation, GRPO, and on-policy distillation, On-Policy Self-Distillation (OPSD) provides training signal that is on-policy, dense, and teacher-free without extensive group sampling cost. 🧵 3/n OPSD instantiates two policies from the same LLM via different conditioning contexts. The student policy conditions only on the problem, while the teacher policy sees both the problem and the ground-truth solution. The training process unfolds in these steps: 1. On-Policy Sampling from the Student: For a given problem, the student policy samples its own response. 2. Teacher-Student Distribution Computation: Both policies evaluate the student's response at each token position. Crucially, the teacher policy is prompted to understand the reference solution and "solve" the problem again before evaluating the student's generation. This ensures the teacher naturally transitions into providing meaningful guidance on the student's generation. (Note the teacher doesn't actually generate—it only produces probability distributions for distillation.) 3. Per-Token Distribution Matching: Minimize the divergence between teacher and student next-token distributions at each position along the student's rollout. 🧵 4/n Experiment Results: On competition-level math benchmarks (AIME 2024/2025, HMMT 2025, AMO-Bench), OPSD improves accuracy over SFT and GRPO, and does so with substantially fewer generated tokens (2k in OPSD vs 16k in GRPO). 🧵 5/n Fewer distillation tokens with dense supervision can match longer GRPO generation tokens with sparse rewards. With equal generations per update but much shorter sequences (2k vs 16k tokens), OPSD achieves comparable or better performance while being 4–8× more token-efficient than GRPO. In practice, this translates to reduced training time and lower computational requirements. 🧵 6/n Another finding is that successful self-distillation requires sufficient model capacity: with fixed problem difficulty and below a capability threshold, the model cannot reliably exploit privileged solutions to produce high-quality teacher distributions. In our scaling study, OPSD provides limited gains over GRPO at the 1.7B scale although OPSD still improves over base and SFT at 1.7B, while 4B and 8B show more improvement. 🧵 7/n Thanks for reading! Work done at UCLA and during my part-time internship at @MetaAI . Huge thanks to my coauthors: @_zhihuixie , Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, @adityagrover_ ! Paper link (arxiv to be released soon): https:// github.com/siyan-zhao/siy an-zhao.github.io/blob/master/assets/papers/OPSD.pdf …

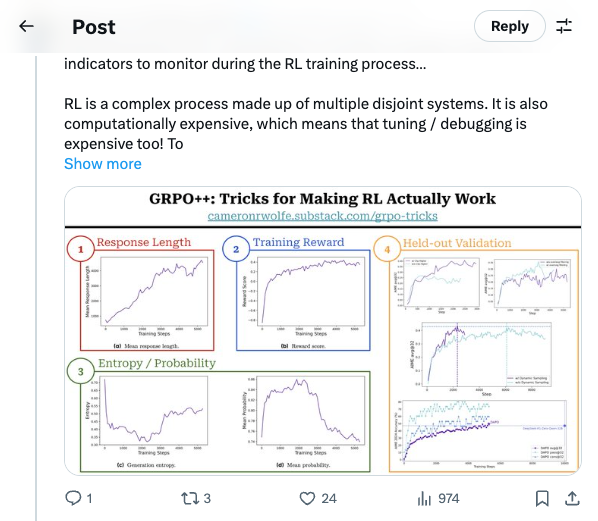
🧵 How do we know if RL is going well or not? Here are some key health indicators to monitor during the RL training process… RL is a complex process made up of multiple disjoint systems. It is also computationally expensive, which means that tuning / debugging is expensive too! To quickly identify issues and iterate on our RL training setup, we need intermediate metrics to efficiently monitor the health of the training process. Key training / policy metrics to monitor include: (1) Response length should increase during reasoning RL as the policy learns how to effectively leverage its long CoT. Average response length is closely related to training stability, but response length does not always monotonically increase—it may stagnate or even decrease. Excessively long response lengths are also a symptom of a faulty RL setup. (2) Training reward should increase in a stable manner throughout training. A noisy or chaotic reward curve is a clear sign of an issue in our RL setup. However, training rewards do not always accurately reflect the model’s performance on held-out data—RL tends to overfit to the training set. (3) Entropy of the policy’s next token prediction distribution serves as a proxy for exploration during RL training. We want entropy to lie in a reasonable range—not too low and not too high. Low entropy means that the next token distribution is too sharp (i.e., all probability is assigned to a single token), which limits exploration. On the other hand, entropy that is too high may indicate the policy is just outputting gibberish. Similarly to entropy, we can also monitor the model’s generation probabilities during RL training. (4) Held-out evaluation should be performed to track our policy’s performance (e.g., average reward or accuracy) as training progresses. Performance should be monitored specifically on held-out validation data to ensure that no reward hacking is taking place. This validation set can be kept (relatively) small to avoid reducing the efficiency of the training process. An example plot of these key intermediate metrics throughout the RL training process from DAPO is provided in the attached image. To iterate upon our RL training setup, we should i) begin with a reasonable setup known to work well, ii) apply interventions to this setup, and iii) monitor these metrics for positive or negative impact. 🧵 Many of these details are covered by DAPO: https:// arxiv.org/abs/2503.14476 You can also check out my post on practical tricks for improving GRPO: https:// cameronrwolfe.substack.com/p/grpo-tricks

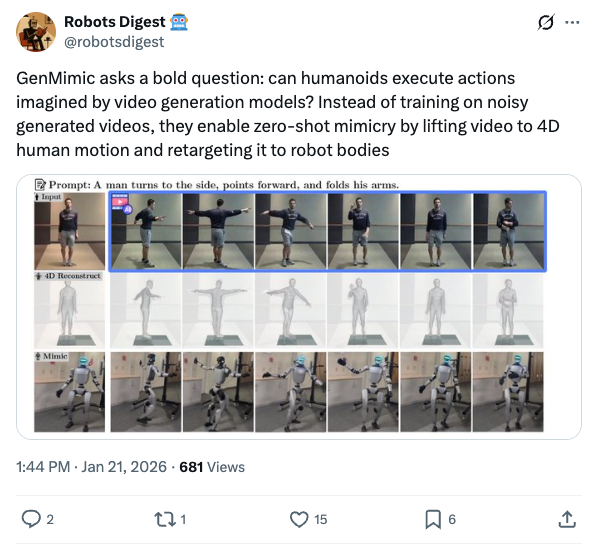
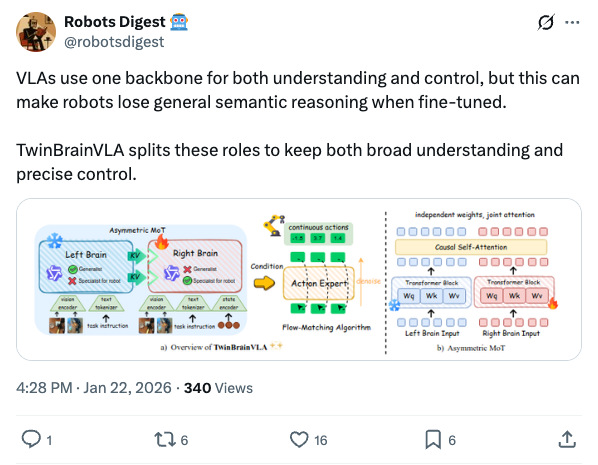
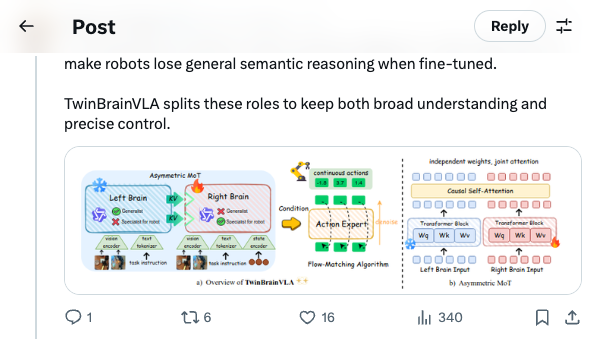
🧵 GenMimic asks a bold question: can humanoids execute actions imagined by video generation models? Instead of training on noisy generated videos, they enable zero-shot mimicry by lifting video to 4D human motion and retargeting it to robot bodies 🧵 VLAs use one backbone for both understanding and control, but this can make robots lose general semantic reasoning when fine-tuned. TwinBrainVLA splits these roles to keep both broad understanding and precise control. 🧵 TwinBrainVLA uses two Vision-Language Models: a frozen “Left Brain” that keeps high-level semantics and a trainable “Right Brain” for embodied perception. They interact through a novel Asymmetric Mixture-of-Transformers mechanism. 🧵 A dedicated Flow-Matching Action Expert uses the Right Brain’s outputs with proprioceptive input to generate continuous robot actions. This design prevents the model from forgetting its open-world knowledge. 🧵 The approach is tested on SimplerEnv and RoboCasa simulation benchmarks, where TwinBrainVLA achieves superior manipulation performance compared to state-of-the-art baselines. This suggests strong generalization and embodied skill learning. 🧵 Key idea: Separating general semantic reasoning from specialized embodied perception helps build robots that keep broad world knowledge while performing precise physical tasks, offering a path toward general-purpose robot intelligence 🧵 paper: https:// arxiv.org/pdf/2601.14133
🧵 Can models understand each other's reasoning? When Model A explains its Chain-of-Thought (CoT) , do Models B, C, and D interpret it the same way? Our new preprint with @davidbau and @csinva explores CoT generalizability (1/7) 🧵 Why does this matter? Faithfulness research (such as @AnthropicAI 's "Reasoning Models Don't Always Say What They Think" and @Zidi 's work) shows CoT doesn't always reflect internal reasoning. Models may hide hints and demonstrate selective faithfulness to intermediate steps. What if explanations serve a different purpose? If Model B follows Model A's reasoning to the same conclusion, maybe these explanations capture something generalizable (even if they are not perfectly "faithful" to either model's internals). (2/7) 🧵 Our evaluation pipeline tests four approaches: Empty CoT: No reasoning provided (baseline) Default: Model generates its own CoT Transfer CoT: Model A's thoughts → Model B Ensemble CoT: Combining multiple models' reasoning We measure cross-model consistency: How often do model pairs reach the same answer? Note that this includes models reaching the same wrong answers! Which approach creates the most generalizable explanations? (3/7) 🧵 Practical implication: CoT Monitorability Cross-model consistency provides a complementary signal: explanations that generalize across models may be more monitorable and trustworthy for oversight. (4/7) 🧵 What do humans actually prefer? Participants rated CoTs on clarity, ease of following, and confidence. We find that Consistency >> Accuracy for predicting preferences. Humans trust explanations that multiple models agree on! (6/7) 🧵 @threadreaderapp please #unroll
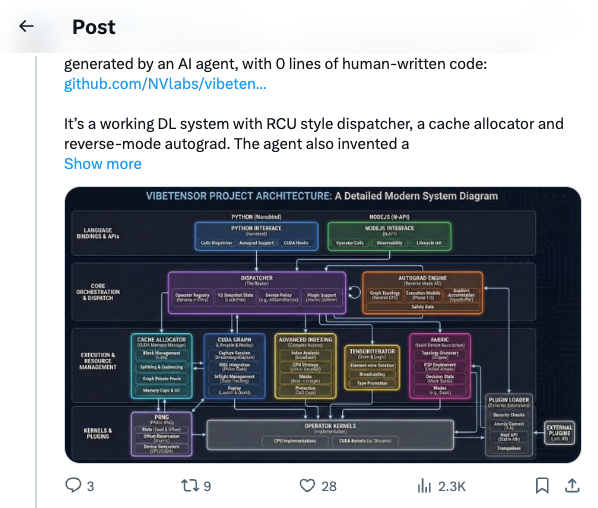
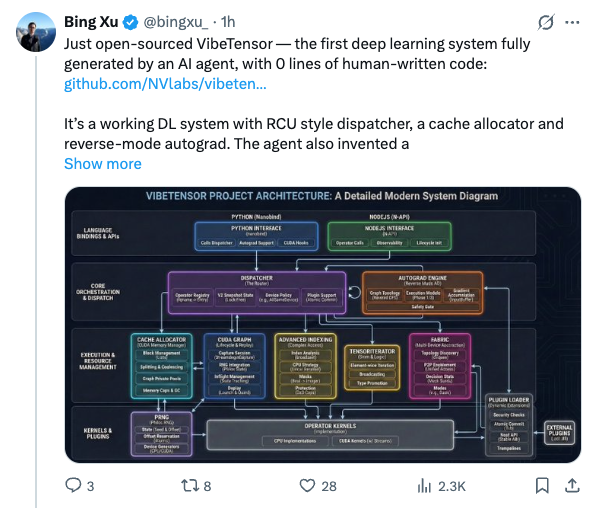
🧵 Just open-sourced VibeTensor — the first deep learning system fully generated by an AI agent, with 0 lines of human-written code: https:// github.com/NVlabs/vibeten sor … It’s a working DL system with RCU style dispatcher, a cache allocator and reverse-mode autograd. The agent also invented a Fabric Tensor system — something that doesn’t exist in any current framework. The Vibe Kernel includes 13 kinds and 47k LOC of generated Triton and CuteDSL kernels with strong performance. VibeTensor was generated by our 4th-generation agent. It shows a “Frankenstein Effect”: the system is correct, but some critical paths are designed in inefficient ways. As a result, performance isn’t comparable to PyTorch. I haven’t written a single line of code since summer 2025. I started this effort after @karpathy 's podcast — I didn’t agree with his arguments, so Terry Chen and I began using it as a stress test for our agents. The “Frankenstein Effect” ended up exposing some of our agent’s limitations — but the direction is clear. 🧵 @tri_dao @cHHillee fyi 🧵 It is methodology issue: human trend to develop correct software first, then optimize. Agents are not human.

🧵 I'm often asked how to land a research job at a frontier AI lab. It's hard, especially without a research background, but I like to point to @kellerjordan0 as an example showing it can be done. Keller graduated from UCSD with no publication record and was working at an AI content moderation startup when he landed a cold call with @bneyshabur (who was at Google) and presented an idea to improve upon Behnam's recent paper. Behnam agreed to mentor him, which led to an ICLR paper. Sadly there's less open research today, but improving upon a researcher's published work is a great way to demonstrate excellence to someone inside a lab and give them the conviction to advocate for an interview. Later, Keller got on @OpenAI 's radar thanks to the NanoGPT speed run he started. All his work was documented and it was easy to measure his success, so the case for hiring him was strong. Keller is one example, but there's plenty of other success stories as well: 🧵 @_sholtodouglas was at McKinsey when he became convinced AI would take off and started doing his own AI side projects. His insightful questions on the JAX GitHub and personal projects impressed @jekbradbury , who invited him to interview at @GoogleDeepMind 🧵 @andy_l_jones was a semi-retired quant when he wrote a paper comparing the impact of scaling pretraining vs scaling test-time compute (before TTC scaling was cool). The paper was impressive not because it achieved SOTA performance on some benchmark, but rather because he made smart design choices, wrote gpu accelerated environments, and ran careful ablations. The fact that he self-published showed initiative. He's now at @Anthropic . https:// x.com/ibab/status/16 69579636563656705 … 🧵 Labs like @OpenAI also hire researchers straight out of undergrad, like @kevin_wang3290 , though the bar is high. Kevin was highly recommended by his advisor and was first author on a NeurIPS 2025 paper. There's a lot of bad NeurIPS papers, but we could tell this was a great one. (Indeed, after he joined OpenAI his paper was one of 4 out of 5,290 to receive a Best Paper award.) His advisor's recommendation counted for a lot because it can be hard to evaluate a researcher just based on a resume or even a paper. https:// x.com/kevin_wang3290 /status/1902753430583525727 … 🧵 A word on comp: I know folks who become quants to make money but 5 years later ask what they're doing with their life. We're at a special time in history. In AI research, you can help positively guide the most important tech of our time *and* get paid well

🧵 Meet the OmniHand Pro 2025 from AGIBOT: High DOF: 19 Total DOF (12 active + 7 passive) in a highly compact, lightweight 750g design. Precision Sensing: Features 150+ taxels with 0.01N force resolution. Critical sensitivity for demanding tasks. Industrial Ready: Provides up to 20N fingertip force, optimized for professional tool manipulation in industrial environments. High-performance architecture, compatible with mainstream robot arms. #AGIBOT #HumanoidNo1 #HumanoidShipmentsNo1 #OmniHandPro2025 #DexterousHand #Automation #HighDOF #HumanoidRobot #AI

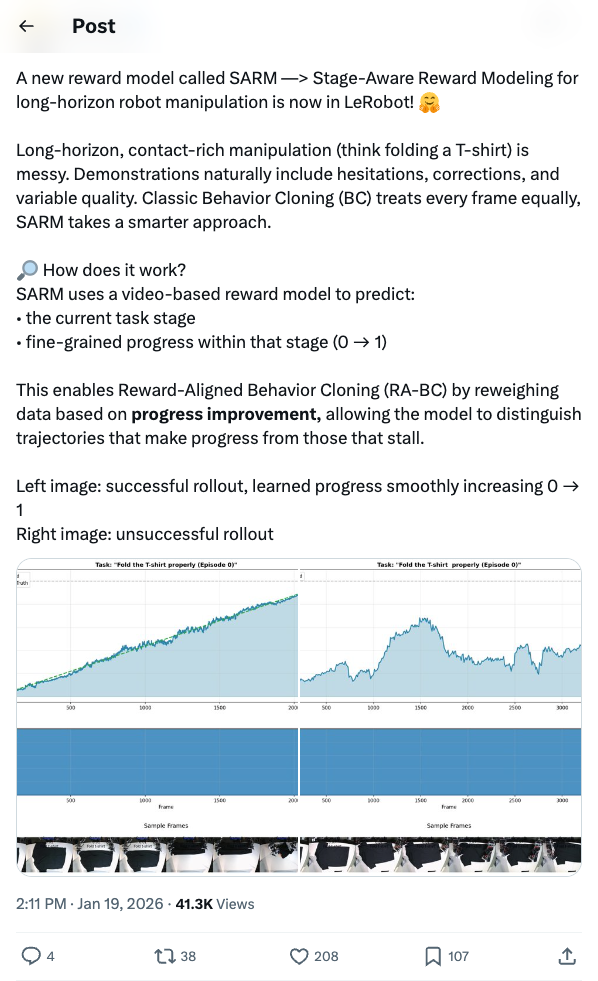
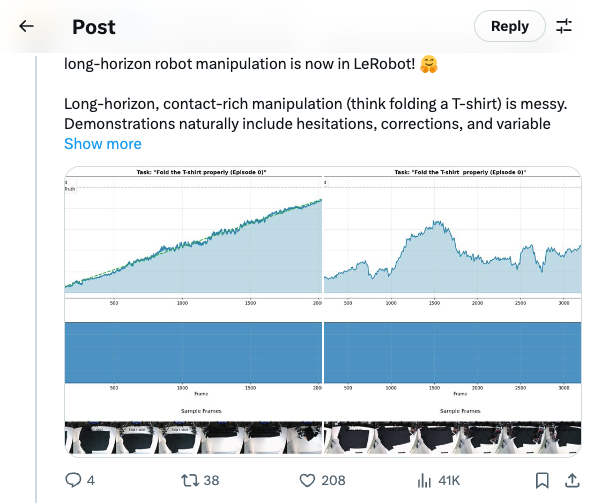
🧵 A new reward model called SARM —> Stage-Aware Reward Modeling for long-horizon robot manipulation is now in LeRobot! Long-horizon, contact-rich manipulation (think folding a T-shirt) is messy. Demonstrations naturally include hesitations, corrections, and variable quality. Classic Behavior Cloning (BC) treats every frame equally, SARM takes a smarter approach. How does it work? SARM uses a video-based reward model to predict: • the current task stage • fine-grained progress within that stage (0 → 1) This enables Reward-Aligned Behavior Cloning (RA-BC) by reweighing data based on progress improvement, allowing the model to distinguish trajectories that make progress from those that stall. Left image: successful rollout, learned progress smoothly increasing 0 → 1 Right image: unsuccessful rollout 🧵 Available now in LeRobot: https:// huggingface.co/docs/lerobot/s arm … Paper https:// arxiv.org/abs/2509.25358 Project website https:// qianzhong-chen.github.io/sarm.github.io/ Credits to the original authors for this awesome work: Qianzhong Chen @QianzhongChen , Justin Yu, Mac Schwager, Pieter Abbeel, Yide Shentu, Philipp Wu
🧵 The day has arrived! #CVPR2026 reviews are scheduled to be released sometime today. NO, we don’t know the exact release time, we’ll find out together with the community. Only our Program Chairs do. Good luck to everyone! 🧵 Dates: https:// cvpr.thecvf.com/Conferences/20 26/Dates …
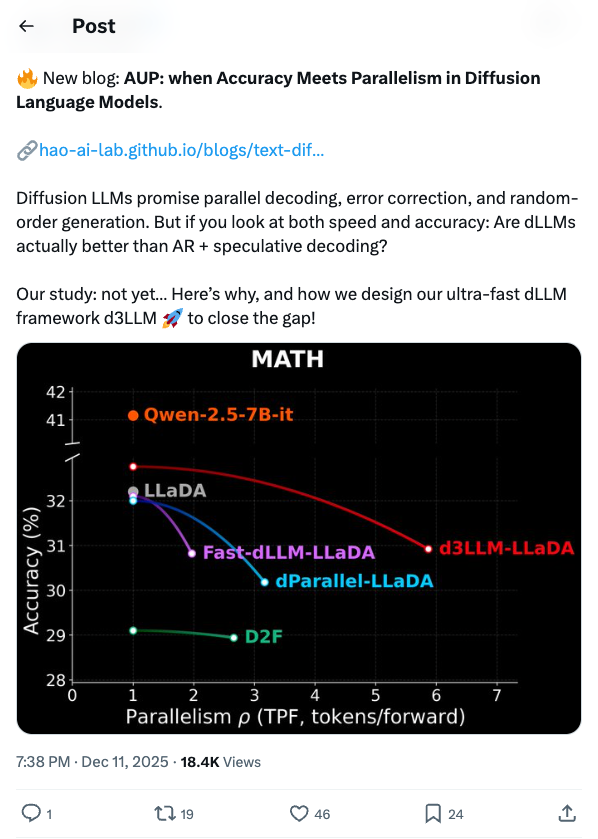
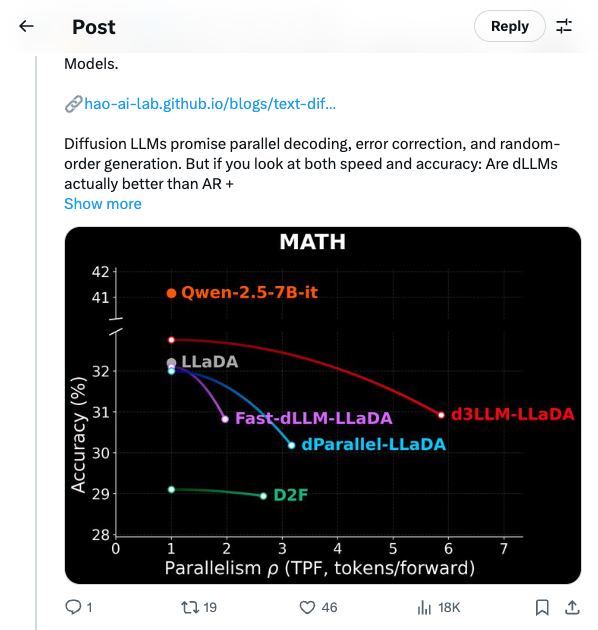
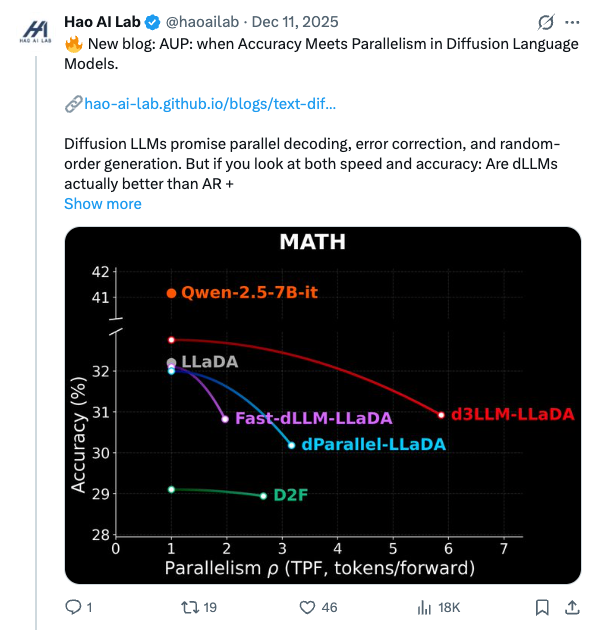
🧵 New blog: AUP: when Accuracy Meets Parallelism in Diffusion Language Models. https:// hao-ai-lab.github.io/blogs/text-dif fusion/ … Diffusion LLMs promise parallel decoding, error correction, and random-order generation. But if you look at both speed and accuracy: Are dLLMs actually better than AR + speculative decoding? Our study: not yet… Here’s why, and how we design our ultra-fast dLLM framework d3LLM to close the gap! 🧵 Key findings: - Existing dLLMs all sit on a clear accuracy–parallelism trade-off: pushing more speedup almost always costs accuracy - Literature mostly reports single metrics (TPS/TPF, or accuracy), overlooking the natural accuracy–parallelism trade-off in dLLMs These insights motivate us to design a new unified metric, AUP, for dLLM 🧵 What is AUP? AUP stands for accuracy under parallelism, which: - jointly considers both accuracy and parallelism - only rewards useful speedups, not “fast but wrong” models - hardware-independent: uses TPF (tokens per forward), remains stable across hardware platforms 🧵 Under AUP, we re-evaluate all open dLLMs along with AR LLMs + strong speculative decoding methods. Here are our results: - Diffusion decoding is genuinely parallel and can be very fast. - But open diffusion systems today pay for speed with accuracy, and the cost is often non-trivial. - AR + speculative decoding remains a very strong baseline when you measure the full trade-off (although the drafting overhead is non-negligible and may increase system complexity). 🧵 Guided by AUP, we then design d3LLM, jointly achieving accuracy and parallelism: - up to 10× speedup over the vanilla LLaDA / Dream, and 5× speedup over AR models (Qwen-2.5-7B) on H100 GPU! - highest AUP score on 9/10 tasks among all dLLMs - with negligible accuracy degradation Try out demo at: https:// 6d0124cae7b92b9d5b.gradio.live 🧵 Key technique innovations in our d3LLM framework: - Pseudo-trajectory distillation (+15% TPF) - Curriculum learning strategy: progressive noise & window length (+25% TPF) - Entropy-based Multi-block Decoding with KV-Cache and refresh (+20% TPF) 🧵 Models, Code, Datasets, and Leaderboard can be found at GitHub repo: https:// github.com/hao-ai-lab/d3L LM … Read the full story:
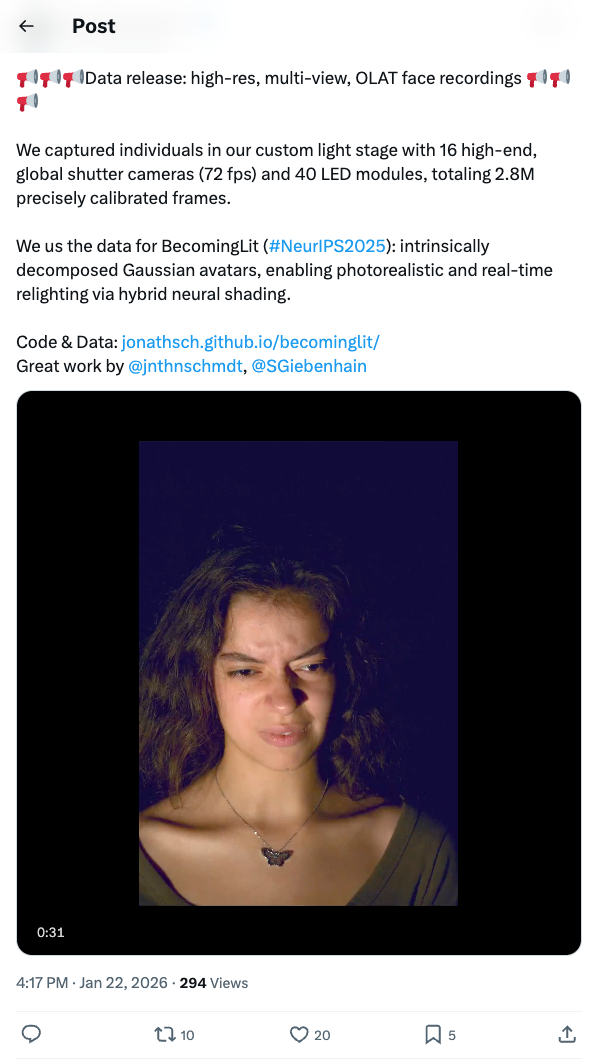
🧵 Data release: high-res, multi-view, OLAT face recordings We captured individuals in our custom light stage with 16 high-end, global shutter cameras (72 fps) and 40 LED modules, totaling 2.8M precisely calibrated frames. We us the data for BecomingLit (#NeurIPS2025): intrinsically decomposed Gaussian avatars, enabling photorealistic and real-time relighting via hybrid neural shading. Code & Data: https:// jonathsch.github.io/becominglit/ Great work by @jnthnschmdt , @SGiebenhain
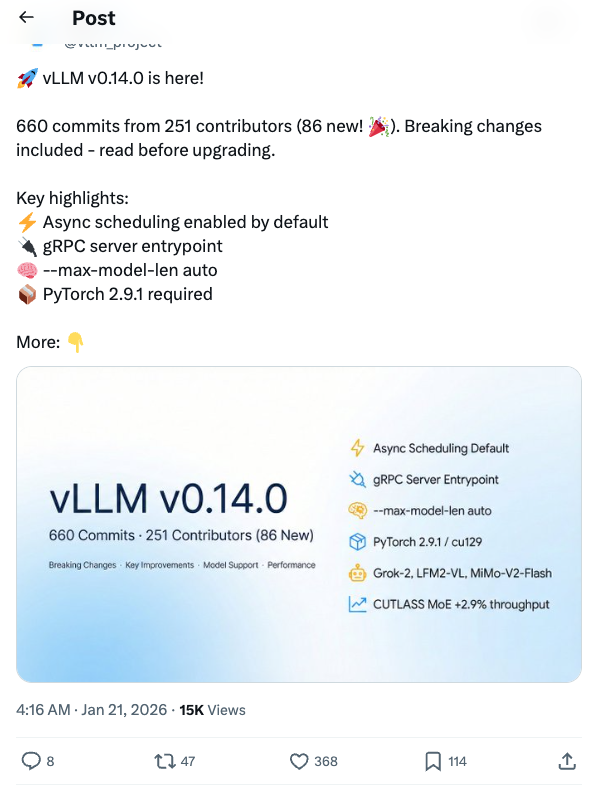
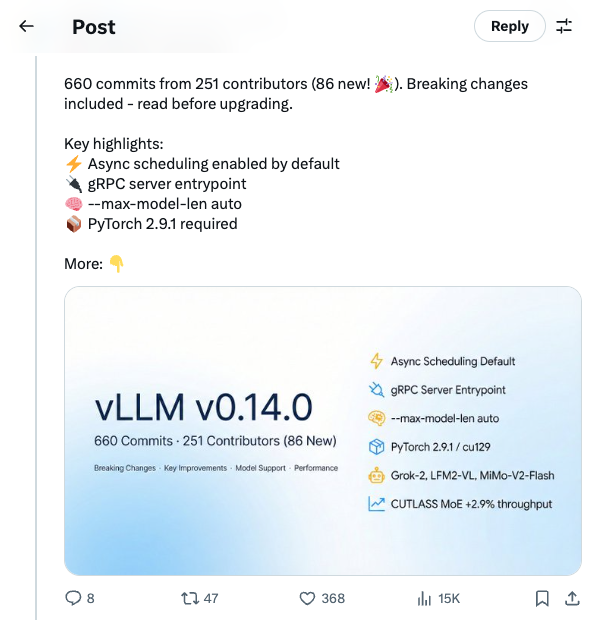
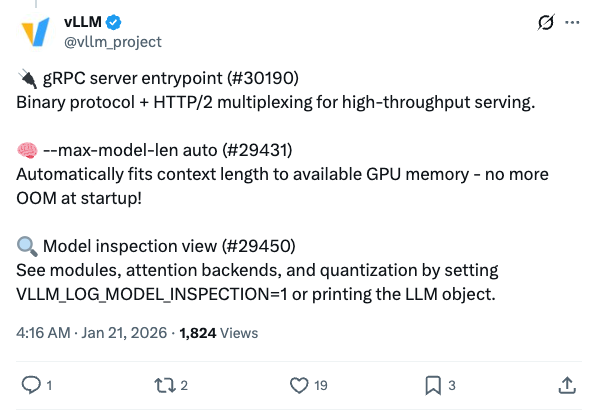
🧵 vLLM v0.14.0 is here! 660 commits from 251 contributors (86 new! ). Breaking changes included - read before upgrading. Key highlights: Async scheduling enabled by default gRPC server entrypoint --max-model-len auto PyTorch 2.9.1 required More: 🧵 What you need to know before upgrading: Async scheduling is now the default. Disable with --no-async-scheduling if needed. PyTorch 2.9.1 is required; default wheel compiled against cu129. Deprecated quantization schemes have been removed. Speculative decoding now fails on unsupported sampling parameters instead of silently ignoring them. 🧵 gRPC server entrypoint (#30190) Binary protocol + HTTP/2 multiplexing for high-throughput serving. --max-model-len auto (#29431) Automatically fits context length to available GPU memory - no more OOM at startup! Model inspection view (#29450) See modules, attention backends, and quantization by setting VLLM_LOG_MODEL_INSPECTION=1 or printing the LLM object. 🧵 New Model Support: Grok-2 with tiktoken tokenizer LFM2-VL vision-language model MiMo-V2-Flash GLM-ASR audio K-EXAONE-236B-A23B MoE LoRA now supports multimodal tower/connector for LLaVA, BLIP2, PaliGemma, Pixtral, and more 🧵 CUTLASS MoE optimizations: 2.9% throughput + 10.8% TTFT improvement via fill(0) optimization Hardware updates: SM103 support B300 Blackwell MoE configs Marlin for Turing (sm75) Large-scale serving: XBO (Extended Dual-Batch Overlap), NIXL asymmetric TP