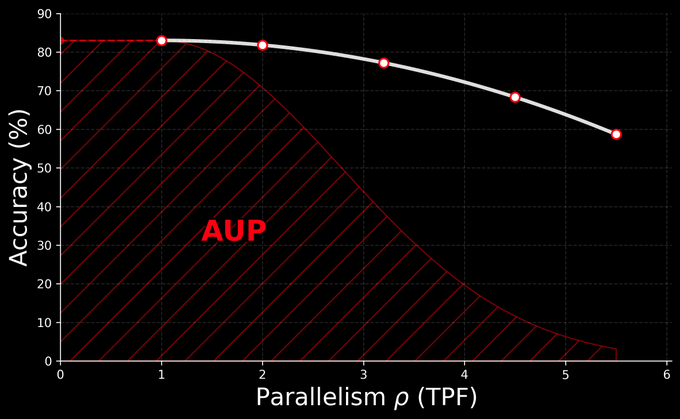
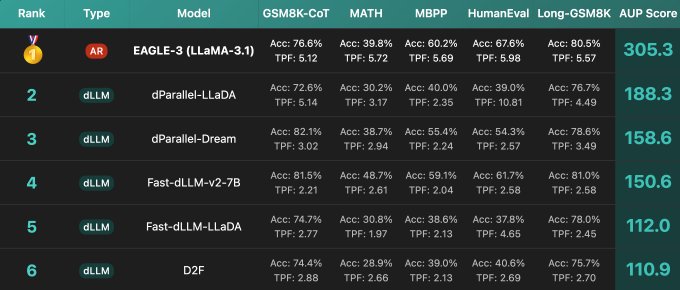
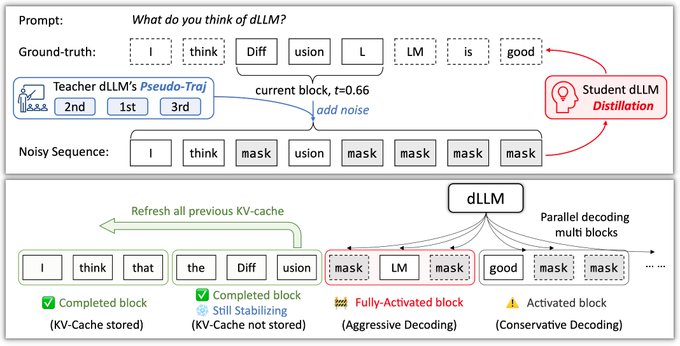
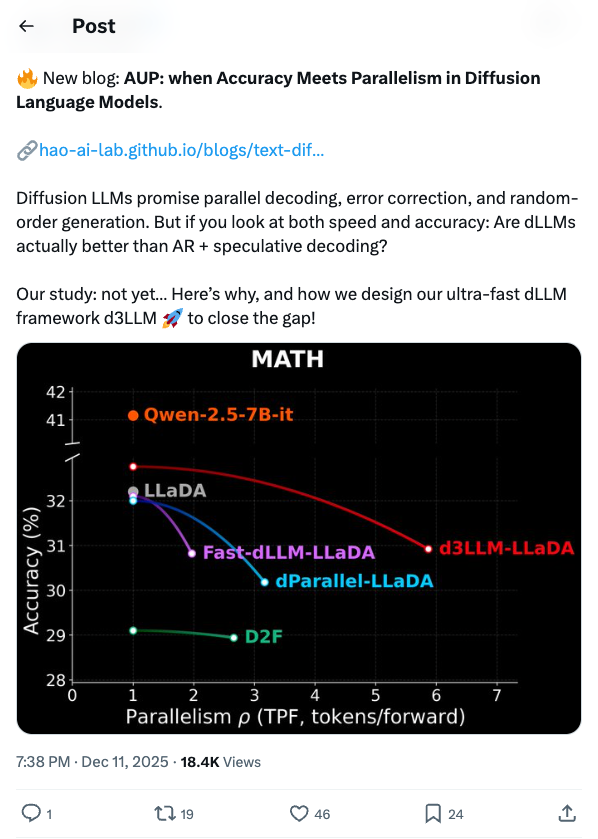
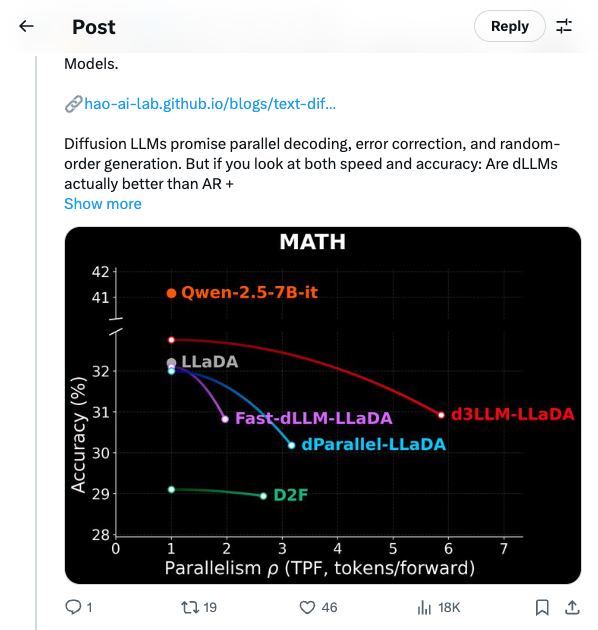
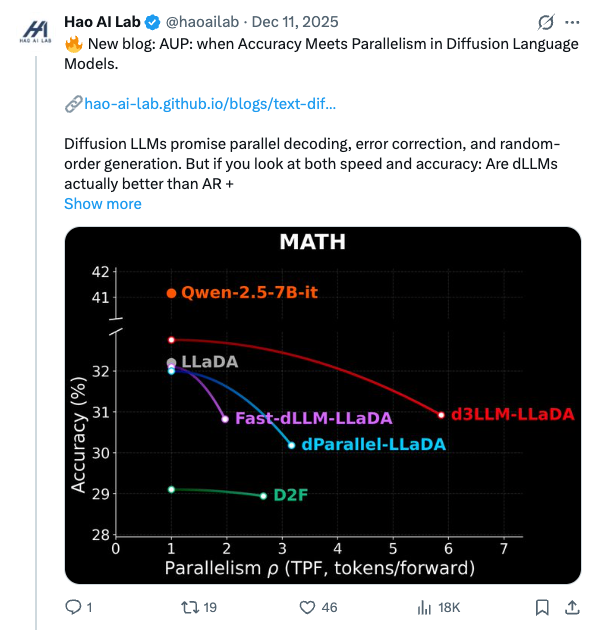
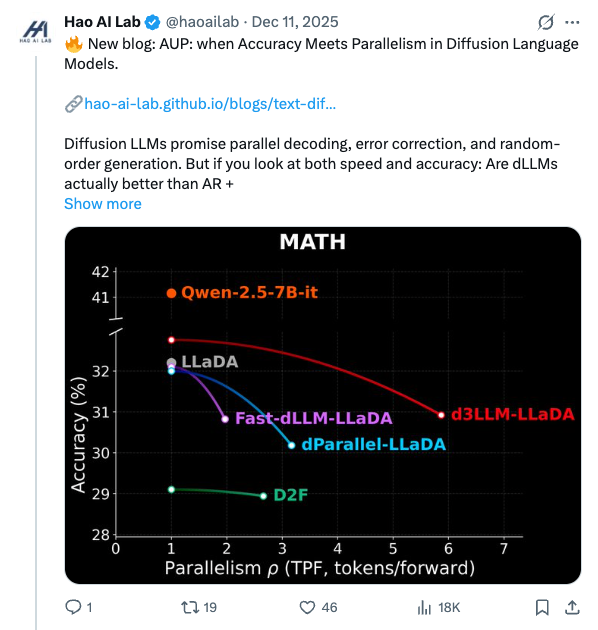
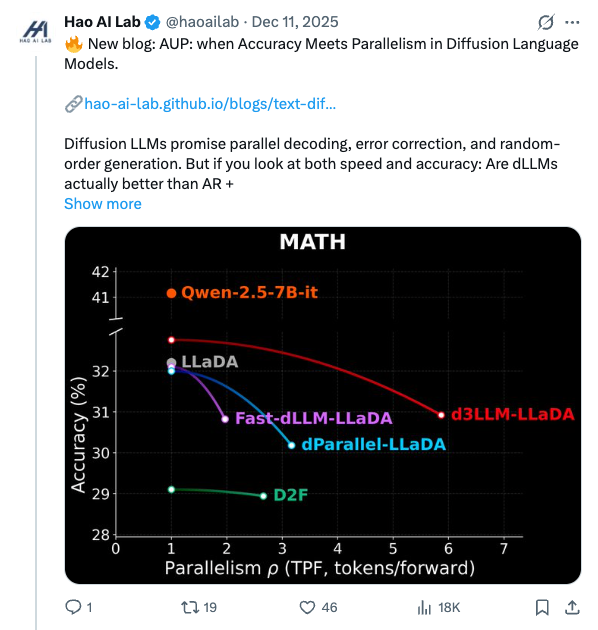
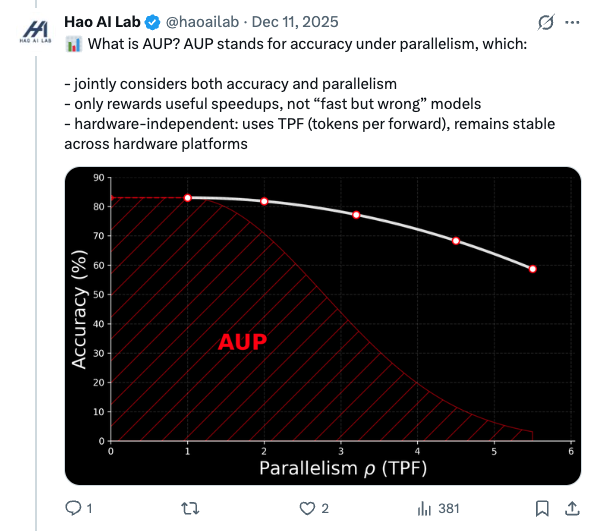
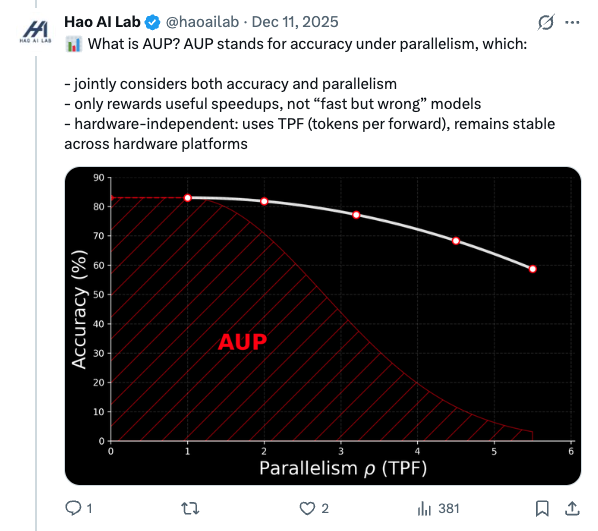
🧵 New blog: AUP: when Accuracy Meets Parallelism in Diffusion Language Models. https:// hao-ai-lab.github.io/blogs/text-dif fusion/ … Diffusion LLMs promise parallel decoding, error correction, and random-order generation. But if you look at both speed and accuracy: Are dLLMs actually better than AR + speculative decoding? Our study: not yet… Here’s why, and how we design our ultra-fast dLLM framework d3LLM to close the gap! 🧵 Key findings: - Existing dLLMs all sit on a clear accuracy–parallelism trade-off: pushing more speedup almost always costs accuracy - Literature mostly reports single metrics (TPS/TPF, or accuracy), overlooking the natural accuracy–parallelism trade-off in dLLMs These insights motivate us to design a new unified metric, AUP, for dLLM 🧵 What is AUP? AUP stands for accuracy under parallelism, which: - jointly considers both accuracy and parallelism - only rewards useful speedups, not “fast but wrong” models - hardware-independent: uses TPF (tokens per forward), remains stable across hardware platforms 🧵 Under AUP, we re-evaluate all open dLLMs along with AR LLMs + strong speculative decoding methods. Here are our results: - Diffusion decoding is genuinely parallel and can be very fast. - But open diffusion systems today pay for speed with accuracy, and the cost is often non-trivial. - AR + speculative decoding remains a very strong baseline when you measure the full trade-off (although the drafting overhead is non-negligible and may increase system complexity). 🧵 Guided by AUP, we then design d3LLM, jointly achieving accuracy and parallelism: - up to 10× speedup over the vanilla LLaDA / Dream, and 5× speedup over AR models (Qwen-2.5-7B) on H100 GPU! - highest AUP score on 9/10 tasks among all dLLMs - with negligible accuracy degradation Try out demo at: https:// 6d0124cae7b92b9d5b.gradio.live 🧵 Key technique innovations in our d3LLM framework: - Pseudo-trajectory distillation (+15% TPF) - Curriculum learning strategy: progressive noise & window length (+25% TPF) - Entropy-based Multi-block Decoding with KV-Cache and refresh (+20% TPF) 🧵 Models, Code, Datasets, and Leaderboard can be found at GitHub repo: https:// github.com/hao-ai-lab/d3L LM … Read the full story:
Thread Screenshots
Images