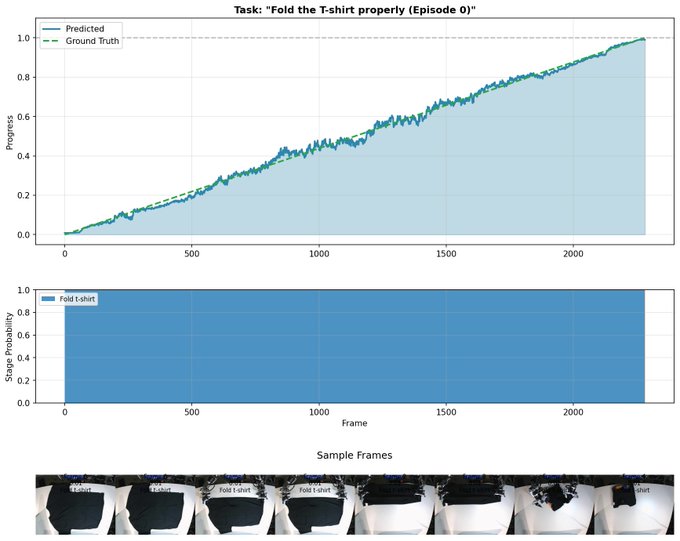
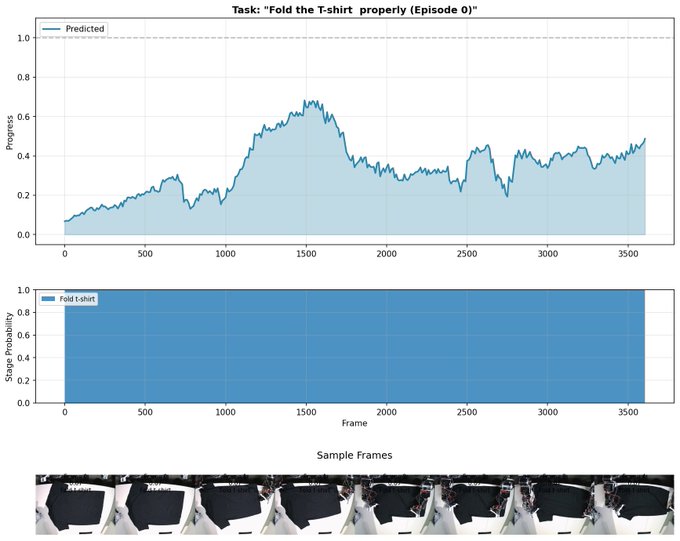
🧵 A new reward model called SARM —> Stage-Aware Reward Modeling for long-horizon robot manipulation is now in LeRobot! Long-horizon, contact-rich manipulation (think folding a T-shirt) is messy. Demonstrations naturally include hesitations, corrections, and variable quality. Classic Behavior Cloning (BC) treats every frame equally, SARM takes a smarter approach. How does it work? SARM uses a video-based reward model to predict: • the current task stage • fine-grained progress within that stage (0 → 1) This enables Reward-Aligned Behavior Cloning (RA-BC) by reweighing data based on progress improvement, allowing the model to distinguish trajectories that make progress from those that stall. Left image: successful rollout, learned progress smoothly increasing 0 → 1 Right image: unsuccessful rollout 🧵 Available now in LeRobot: https:// huggingface.co/docs/lerobot/s arm … Paper https:// arxiv.org/abs/2509.25358 Project website https:// qianzhong-chen.github.io/sarm.github.io/ Credits to the original authors for this awesome work: Qianzhong Chen @QianzhongChen , Justin Yu, Mac Schwager, Pieter Abbeel, Yide Shentu, Philipp Wu
Thread Screenshots
Images