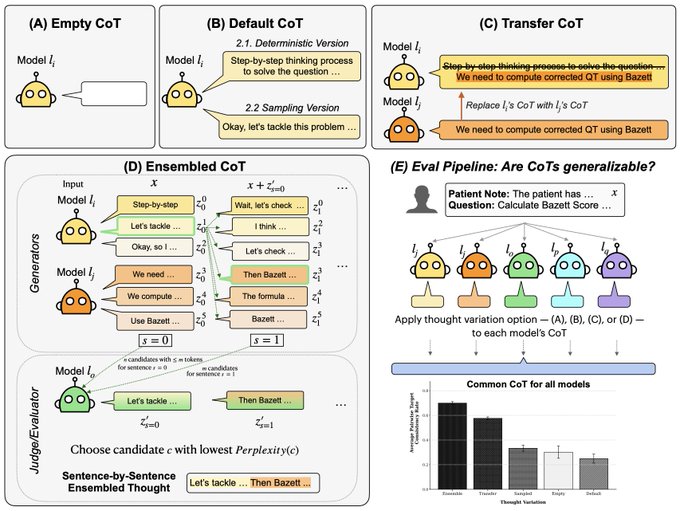
🧵 Can models understand each other's reasoning? When Model A explains its Chain-of-Thought (CoT) , do Models B, C, and D interpret it the same way? Our new preprint with @davidbau and @csinva explores CoT generalizability (1/7) 🧵 Why does this matter? Faithfulness research (such as @AnthropicAI 's "Reasoning Models Don't Always Say What They Think" and @Zidi 's work) shows CoT doesn't always reflect internal reasoning. Models may hide hints and demonstrate selective faithfulness to intermediate steps. What if explanations serve a different purpose? If Model B follows Model A's reasoning to the same conclusion, maybe these explanations capture something generalizable (even if they are not perfectly "faithful" to either model's internals). (2/7) 🧵 Our evaluation pipeline tests four approaches: Empty CoT: No reasoning provided (baseline) Default: Model generates its own CoT Transfer CoT: Model A's thoughts → Model B Ensemble CoT: Combining multiple models' reasoning We measure cross-model consistency: How often do model pairs reach the same answer? Note that this includes models reaching the same wrong answers! Which approach creates the most generalizable explanations? (3/7) 🧵 Practical implication: CoT Monitorability Cross-model consistency provides a complementary signal: explanations that generalize across models may be more monitorable and trustworthy for oversight. (4/7) 🧵 What do humans actually prefer? Participants rated CoTs on clarity, ease of following, and confidence. We find that Consistency >> Accuracy for predicting preferences. Humans trust explanations that multiple models agree on! (6/7) 🧵 @threadreaderapp please #unroll
Thread Screenshots

Images