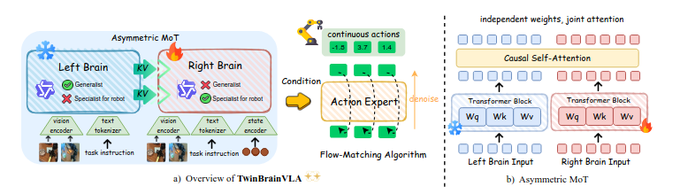
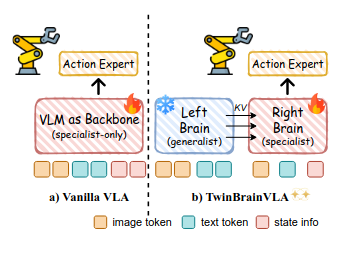
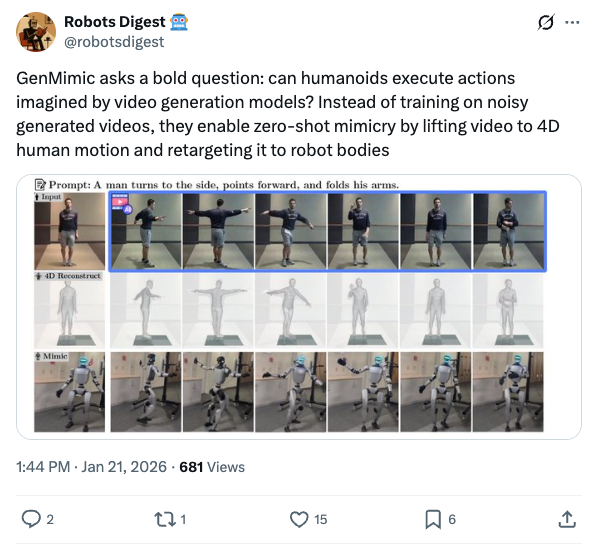
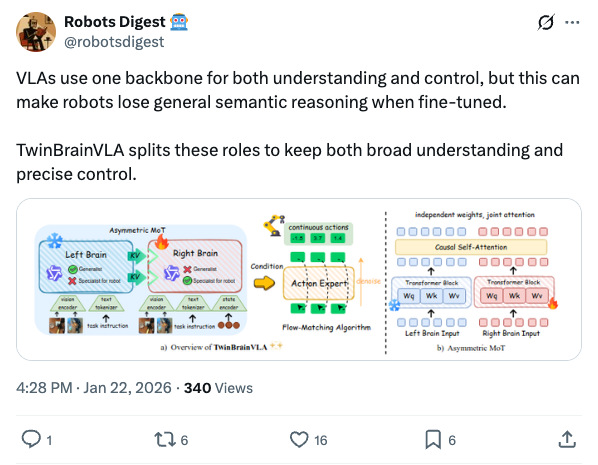
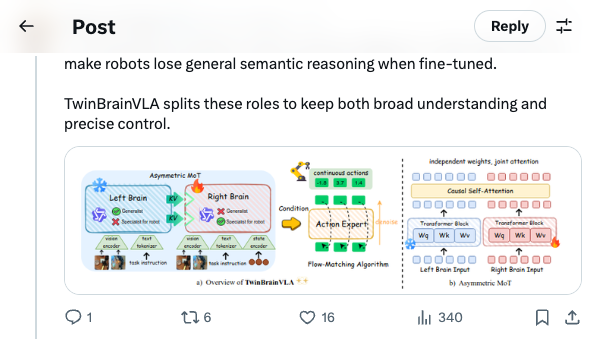
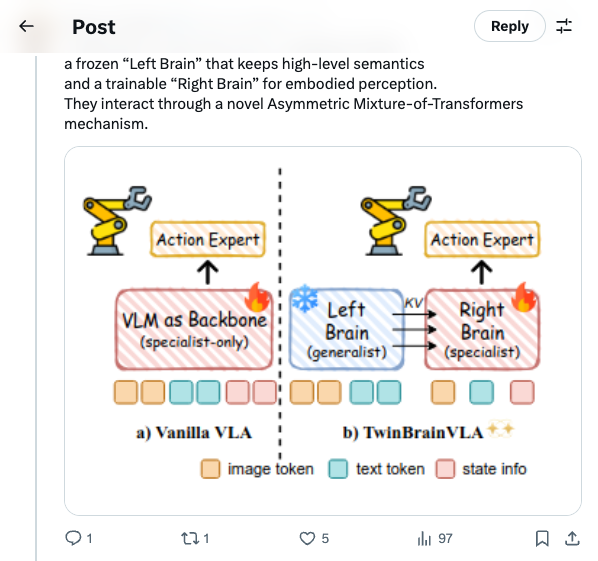
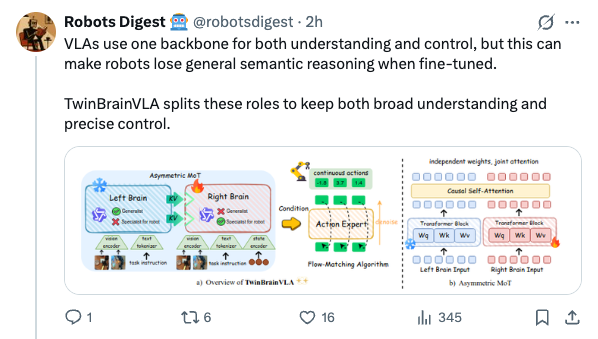
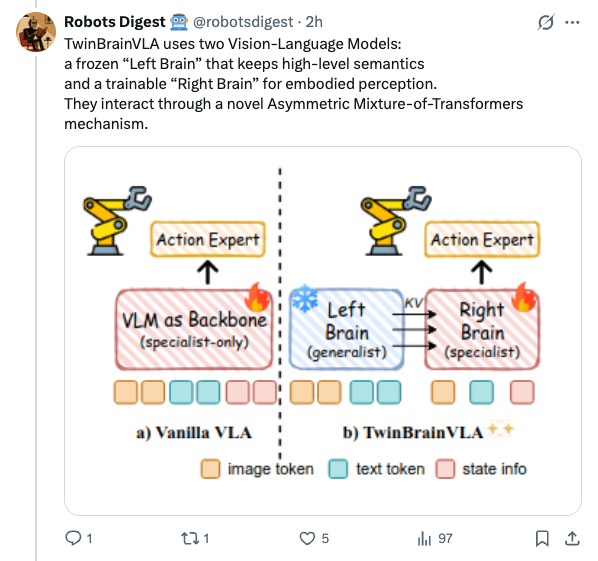
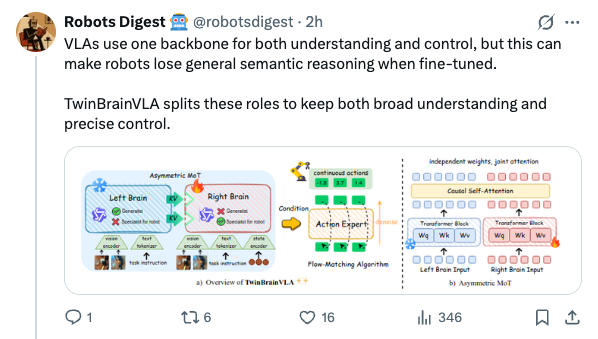
🧵 GenMimic asks a bold question: can humanoids execute actions imagined by video generation models? Instead of training on noisy generated videos, they enable zero-shot mimicry by lifting video to 4D human motion and retargeting it to robot bodies 🧵 VLAs use one backbone for both understanding and control, but this can make robots lose general semantic reasoning when fine-tuned. TwinBrainVLA splits these roles to keep both broad understanding and precise control. 🧵 TwinBrainVLA uses two Vision-Language Models: a frozen “Left Brain” that keeps high-level semantics and a trainable “Right Brain” for embodied perception. They interact through a novel Asymmetric Mixture-of-Transformers mechanism. 🧵 A dedicated Flow-Matching Action Expert uses the Right Brain’s outputs with proprioceptive input to generate continuous robot actions. This design prevents the model from forgetting its open-world knowledge. 🧵 The approach is tested on SimplerEnv and RoboCasa simulation benchmarks, where TwinBrainVLA achieves superior manipulation performance compared to state-of-the-art baselines. This suggests strong generalization and embodied skill learning. 🧵 Key idea: Separating general semantic reasoning from specialized embodied perception helps build robots that keep broad world knowledge while performing precise physical tasks, offering a path toward general-purpose robot intelligence 🧵 paper: https:// arxiv.org/pdf/2601.14133
Thread Screenshots
Images