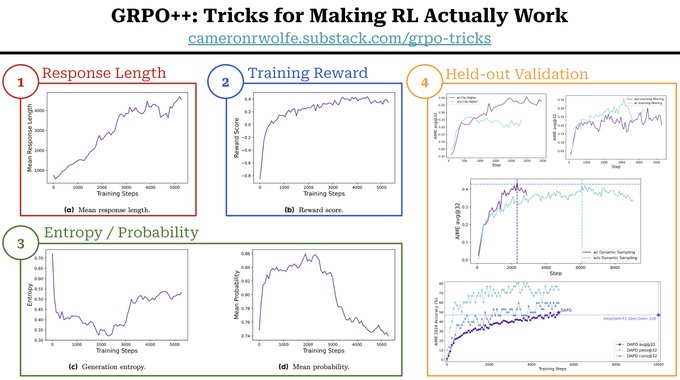
🧵 How do we know if RL is going well or not? Here are some key health indicators to monitor during the RL training process… RL is a complex process made up of multiple disjoint systems. It is also computationally expensive, which means that tuning / debugging is expensive too! To quickly identify issues and iterate on our RL training setup, we need intermediate metrics to efficiently monitor the health of the training process. Key training / policy metrics to monitor include: (1) Response length should increase during reasoning RL as the policy learns how to effectively leverage its long CoT. Average response length is closely related to training stability, but response length does not always monotonically increase—it may stagnate or even decrease. Excessively long response lengths are also a symptom of a faulty RL setup. (2) Training reward should increase in a stable manner throughout training. A noisy or chaotic reward curve is a clear sign of an issue in our RL setup. However, training rewards do not always accurately reflect the model’s performance on held-out data—RL tends to overfit to the training set. (3) Entropy of the policy’s next token prediction distribution serves as a proxy for exploration during RL training. We want entropy to lie in a reasonable range—not too low and not too high. Low entropy means that the next token distribution is too sharp (i.e., all probability is assigned to a single token), which limits exploration. On the other hand, entropy that is too high may indicate the policy is just outputting gibberish. Similarly to entropy, we can also monitor the model’s generation probabilities during RL training. (4) Held-out evaluation should be performed to track our policy’s performance (e.g., average reward or accuracy) as training progresses. Performance should be monitored specifically on held-out validation data to ensure that no reward hacking is taking place. This validation set can be kept (relatively) small to avoid reducing the efficiency of the training process. An example plot of these key intermediate metrics throughout the RL training process from DAPO is provided in the attached image. To iterate upon our RL training setup, we should i) begin with a reasonable setup known to work well, ii) apply interventions to this setup, and iii) monitor these metrics for positive or negative impact. 🧵 Many of these details are covered by DAPO: https:// arxiv.org/abs/2503.14476 You can also check out my post on practical tricks for improving GRPO: https:// cameronrwolfe.substack.com/p/grpo-tricks
Thread Screenshots

Images