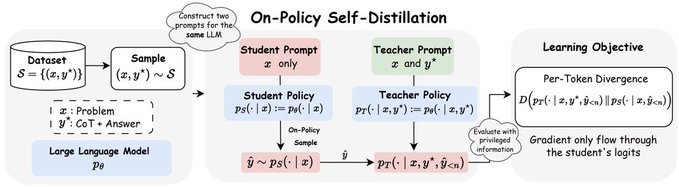
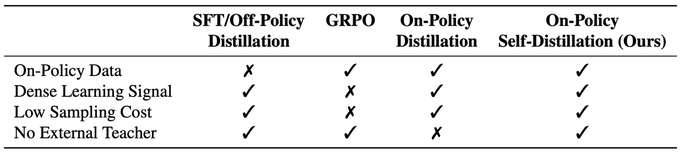
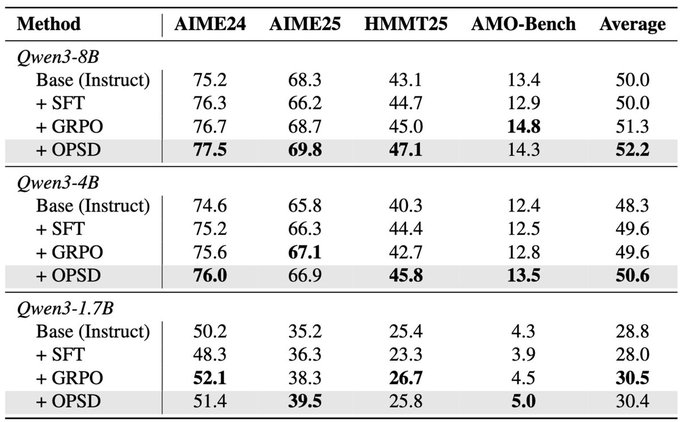
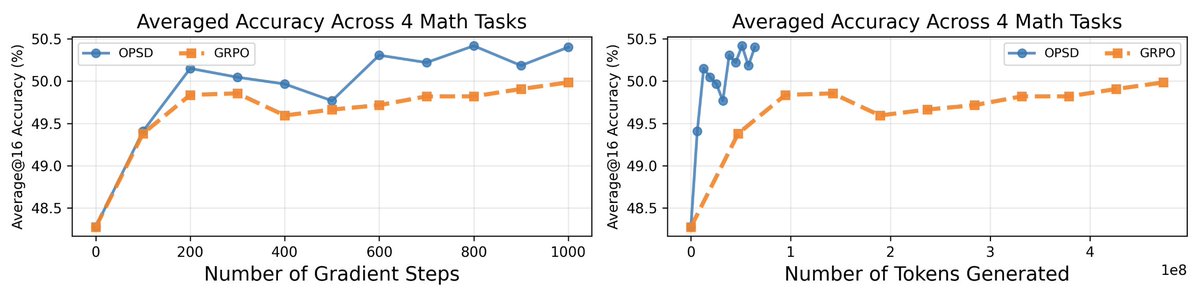
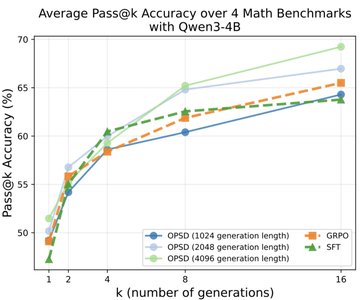
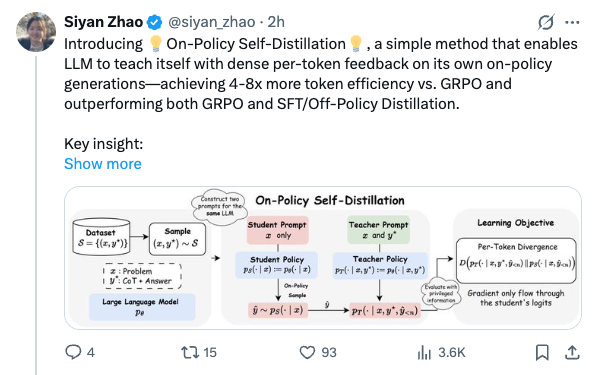
🧵 Introducing On-Policy Self-Distillation, a simple method that enables LLM to teach itself with dense per-token feedback on its own on-policy generations—achieving 4-8x more token efficiency vs. GRPO and outperforming both GRPO and SFT/Off-Policy Distillation. Key insight: like a student reviewing solutions, rationalizing them, and correcting prior mistakes, an LLM can be conditioned on privileged info (e.g., correct solution or a reasoning trace) and supervise its weaker self—the version without such access—by matching the privileged-info-induced distribution from itself. Blog: https:// siyan-zhao.github.io/blog/2026/opsd/ 🧵 2/n As compared to SFT/off-policy distillation, GRPO, and on-policy distillation, On-Policy Self-Distillation (OPSD) provides training signal that is on-policy, dense, and teacher-free without extensive group sampling cost. 🧵 3/n OPSD instantiates two policies from the same LLM via different conditioning contexts. The student policy conditions only on the problem, while the teacher policy sees both the problem and the ground-truth solution. The training process unfolds in these steps: 1. On-Policy Sampling from the Student: For a given problem, the student policy samples its own response. 2. Teacher-Student Distribution Computation: Both policies evaluate the student's response at each token position. Crucially, the teacher policy is prompted to understand the reference solution and "solve" the problem again before evaluating the student's generation. This ensures the teacher naturally transitions into providing meaningful guidance on the student's generation. (Note the teacher doesn't actually generate—it only produces probability distributions for distillation.) 3. Per-Token Distribution Matching: Minimize the divergence between teacher and student next-token distributions at each position along the student's rollout. 🧵 4/n Experiment Results: On competition-level math benchmarks (AIME 2024/2025, HMMT 2025, AMO-Bench), OPSD improves accuracy over SFT and GRPO, and does so with substantially fewer generated tokens (2k in OPSD vs 16k in GRPO). 🧵 5/n Fewer distillation tokens with dense supervision can match longer GRPO generation tokens with sparse rewards. With equal generations per update but much shorter sequences (2k vs 16k tokens), OPSD achieves comparable or better performance while being 4–8× more token-efficient than GRPO. In practice, this translates to reduced training time and lower computational requirements. 🧵 6/n Another finding is that successful self-distillation requires sufficient model capacity: with fixed problem difficulty and below a capability threshold, the model cannot reliably exploit privileged solutions to produce high-quality teacher distributions. In our scaling study, OPSD provides limited gains over GRPO at the 1.7B scale although OPSD still improves over base and SFT at 1.7B, while 4B and 8B show more improvement. 🧵 7/n Thanks for reading! Work done at UCLA and during my part-time internship at @MetaAI . Huge thanks to my coauthors: @_zhihuixie , Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, @adityagrover_ ! Paper link (arxiv to be released soon): https:// github.com/siyan-zhao/siy an-zhao.github.io/blob/master/assets/papers/OPSD.pdf …
Thread Screenshots
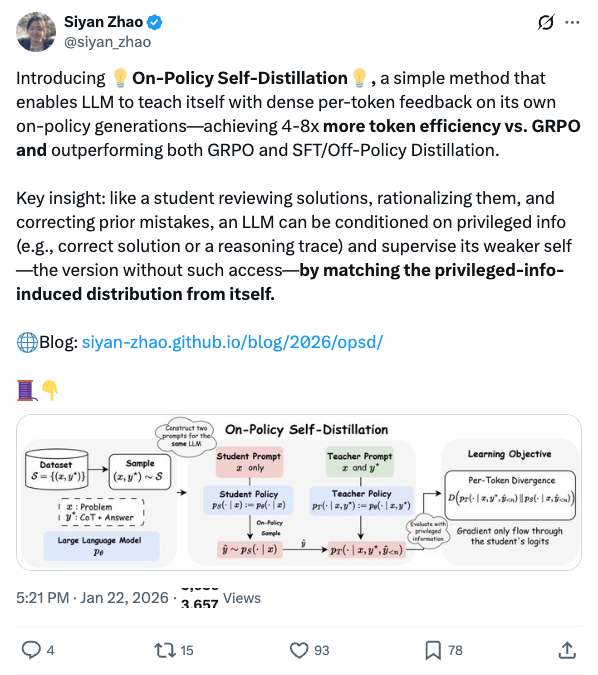
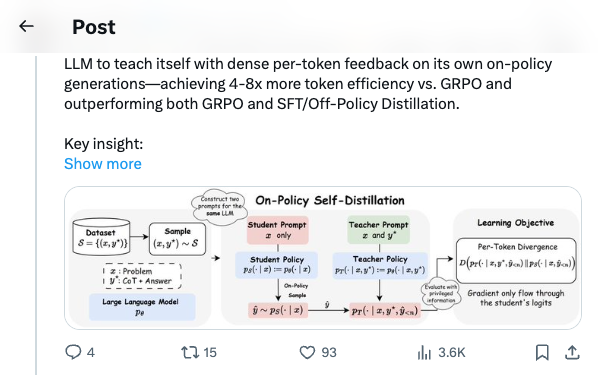

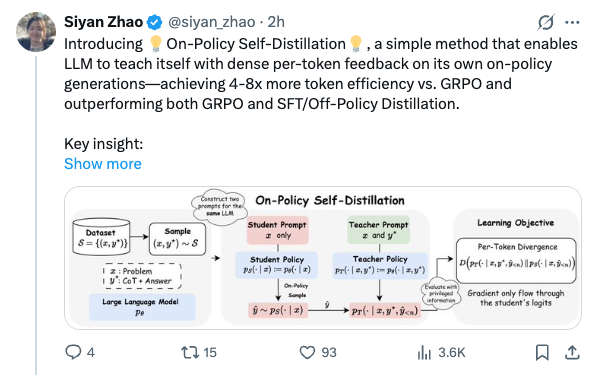


Images