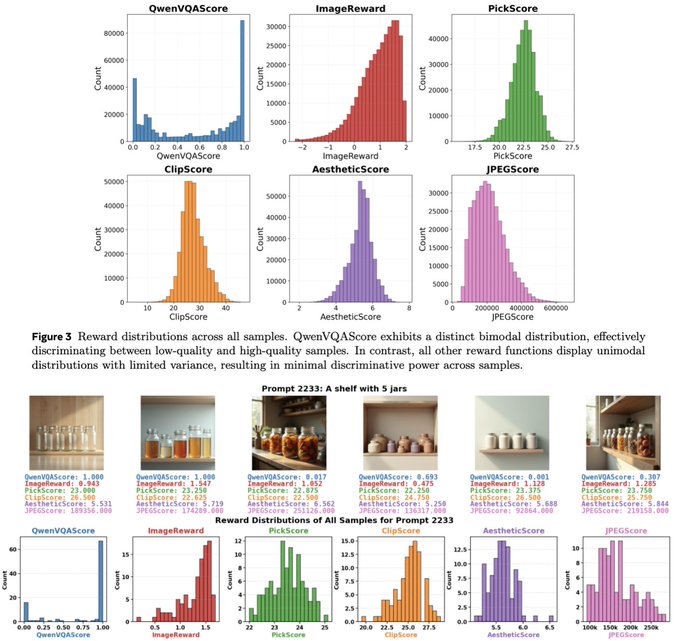
🧵 Multimodal T2I models generate "reasoning" for image generation—but this often doesn't help produce better images! Can we fix this? Our reward-weighted post-training enables fully automatic joint text-image generation, boosting prompt alignment and knowledge-based generation. 🧵 Key findings: → VQAScore (an eval metric) + Qwen2.5-VL is a better reward than existing T2I reward models → For training data, weakness-targeted prompts beat both general image captions and benchmark-specific prompts → Reward-weighting both modalities jointly is best 2/n 🧵 Results on 4 diverse benchmarks and full details in the paper: https:// arxiv.org/abs/2601.04339 This work was done at @AIatMeta . Thanks to my collaborators @tokenpilled65B @XiaochuangHan @huyushi98 @em_dinan @kamath_amita @michal_drozdzal @ReyhaneAskari @LukeZettlemoyer @gh_marjan 3/n
Thread Screenshots

Images