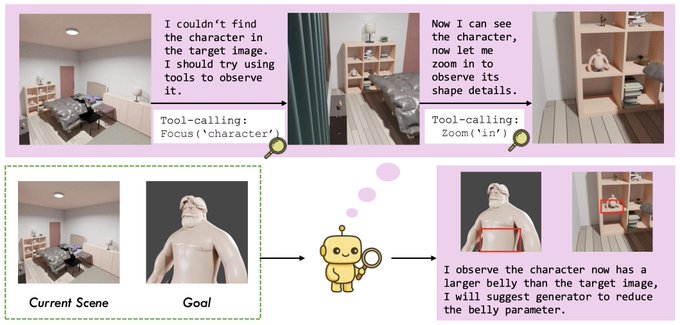
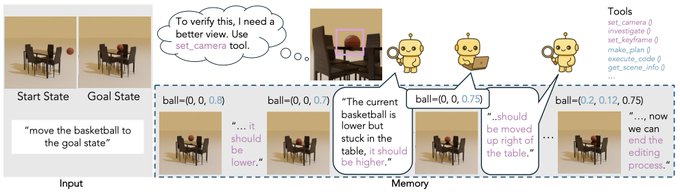
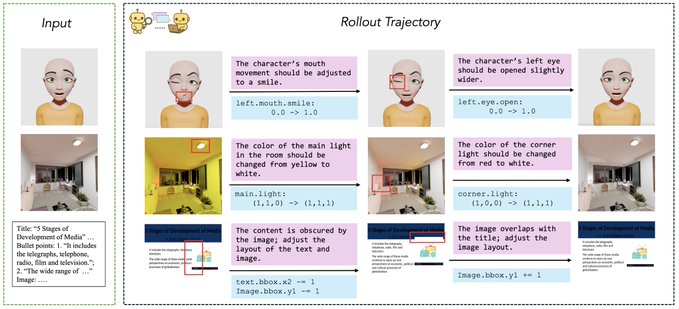
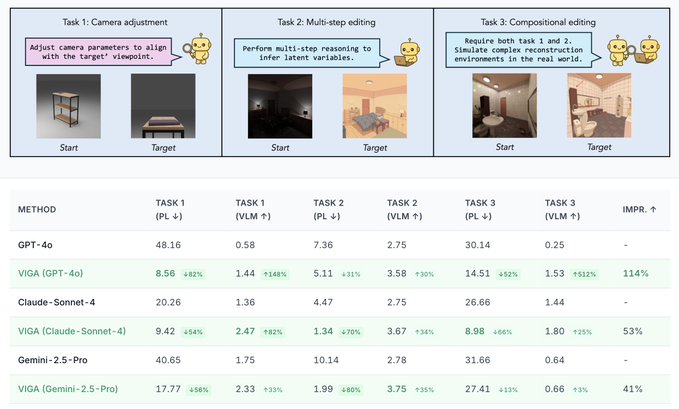
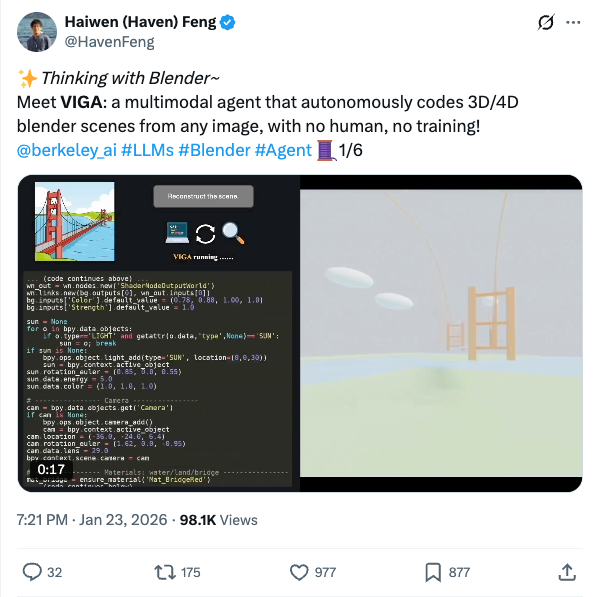
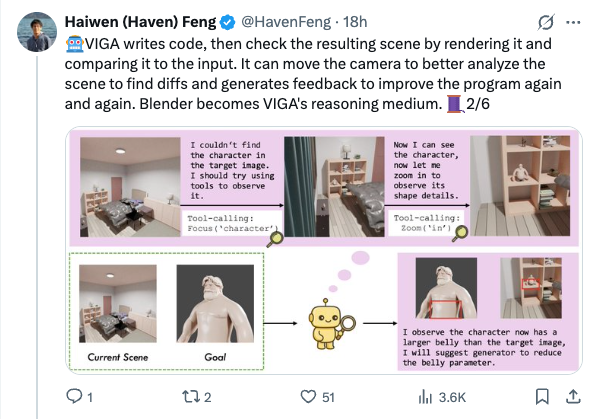
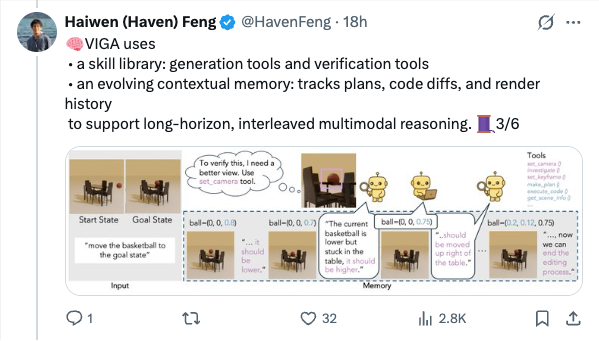
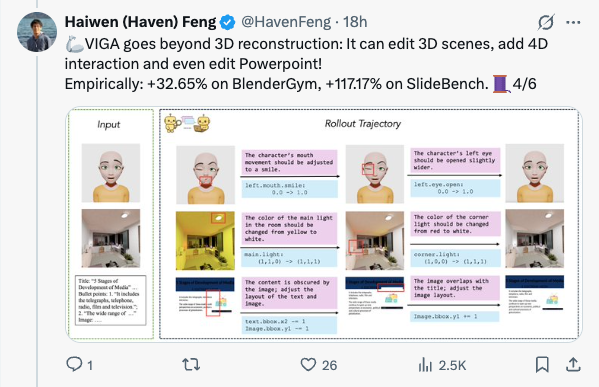
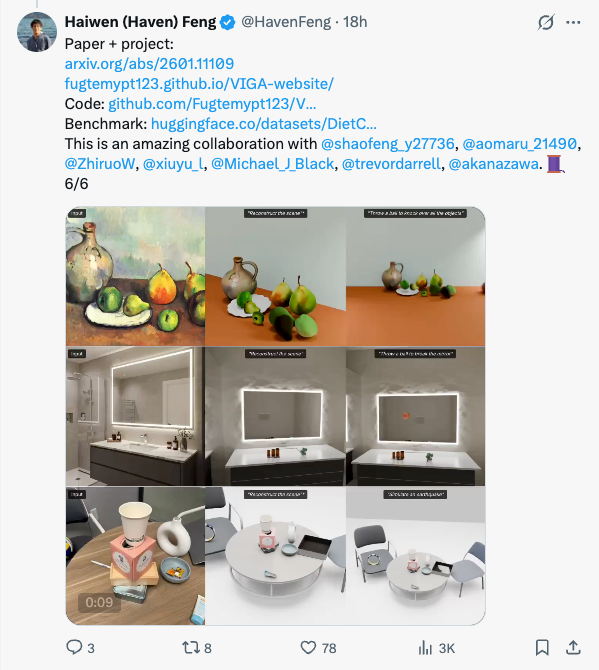
🧵 Thinking with Blender~ Meet VIGA: a multimodal agent that autonomously codes 3D/4D blender scenes from any image, with no human, no training! @berkeley_ai #LLMs #Blender #Agent 1/6 🧵 VIGA writes code, then check the resulting scene by rendering it and comparing it to the input. It can move the camera to better analyze the scene to find diffs and generates feedback to improve the program again and again. Blender becomes VIGA's reasoning medium. 2/6 🧵 VIGA uses • a skill library: generation tools and verification tools • an evolving contextual memory: tracks plans, code diffs, and render history to support long-horizon, interleaved multimodal reasoning. 3/6 🧵 VIGA goes beyond 3D reconstruction: It can edit 3D scenes, add 4D interaction and even edit Powerpoint! Empirically: +32.65% on BlenderGym, +117.17% on SlideBench. 4/6 🧵 We also release BlenderBench: a harder benchmark for agentic inverse graphics. It stress tests fine-level camera control, multi-step edits, compositional changes. On its hardest task, VIGA achieves a +512% gain! 5/6 🧵 Paper + project: https:// arxiv.org/abs/2601.11109 https:// fugtemypt123.github.io/VIGA-website/ Code: https:// github.com/Fugtemypt123/V IGA-release … Benchmark: https:// huggingface.co/datasets/DietC oke4671/BlenderBench … This is an amazing collaboration with @shaofeng_y27736 , @aomaru_21490 , @ZhiruoW , @xiuyu_l , @Michael_J_Black , @trevordarrell , @akanazawa . 6/6
Thread Screenshots
Images