Academic Tweets
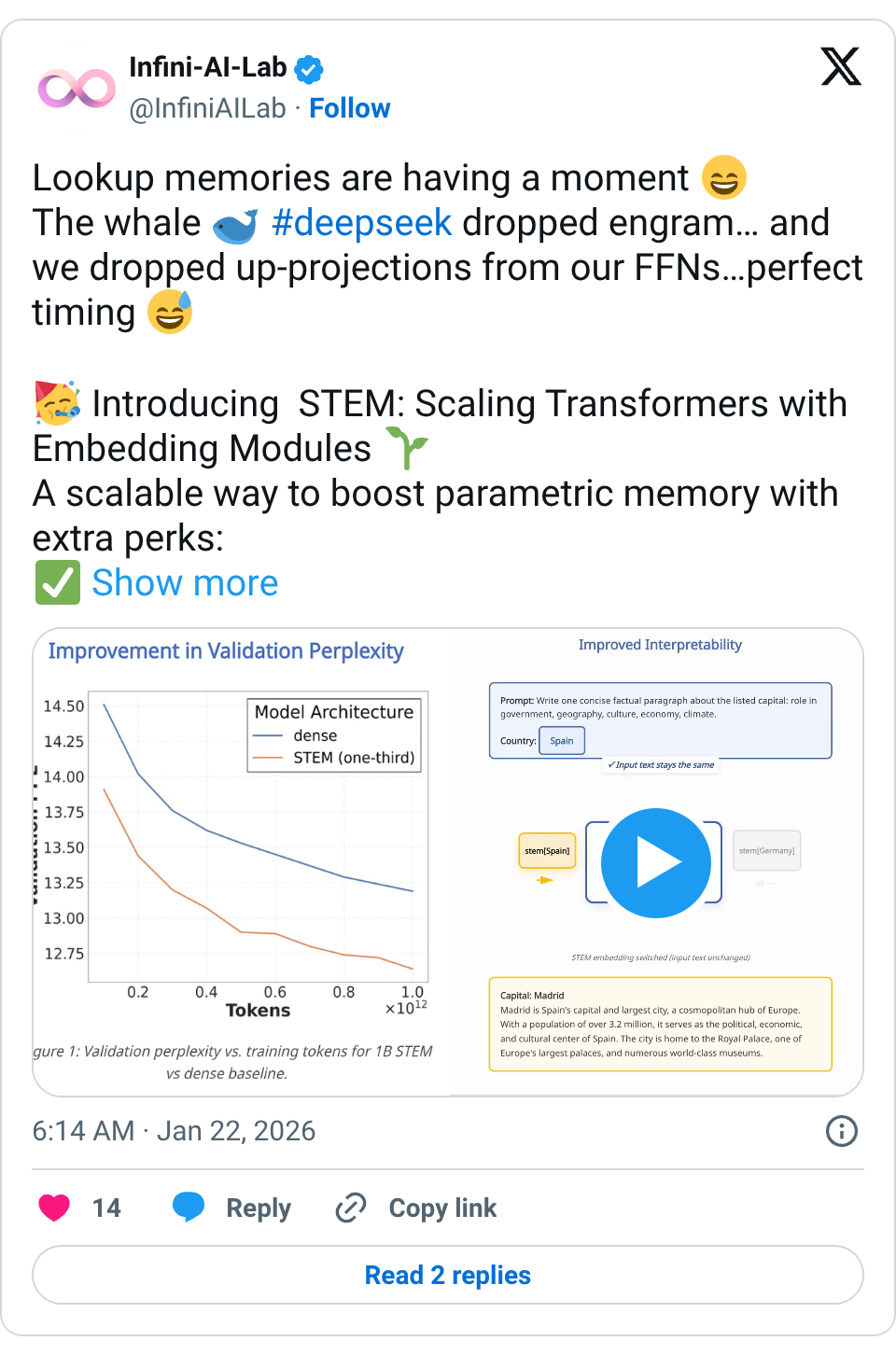
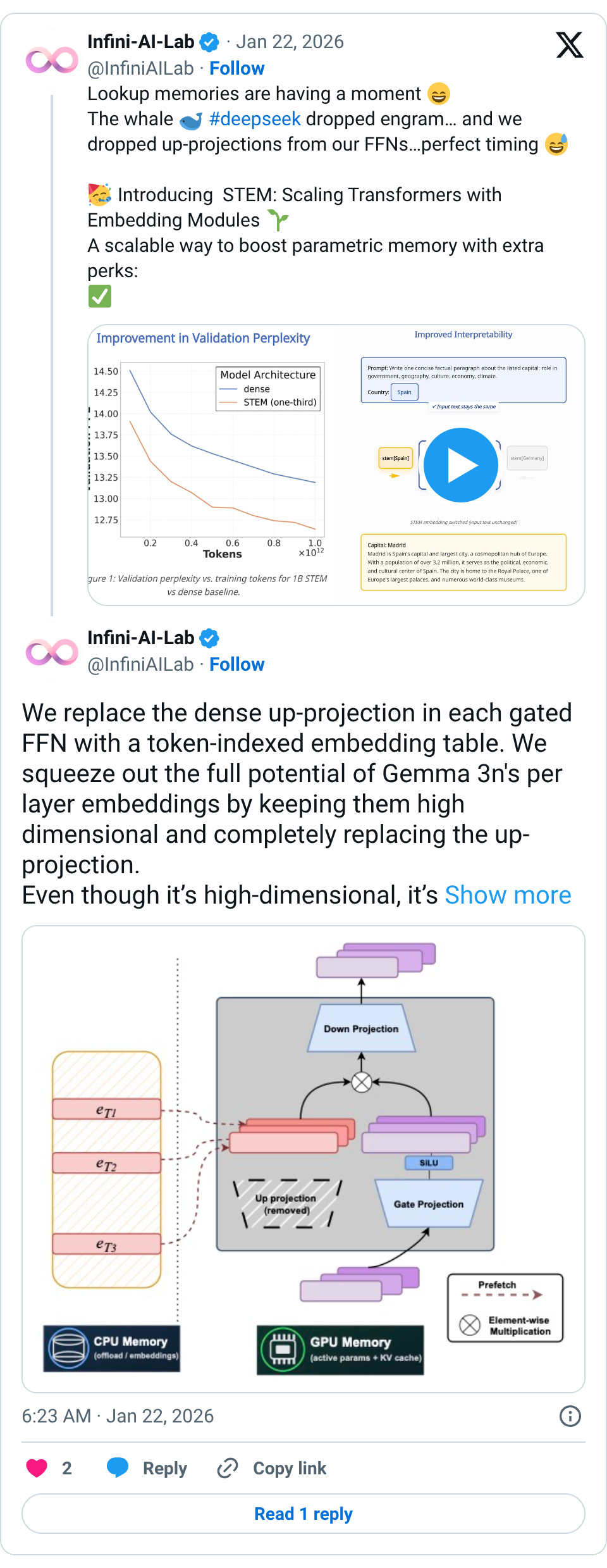
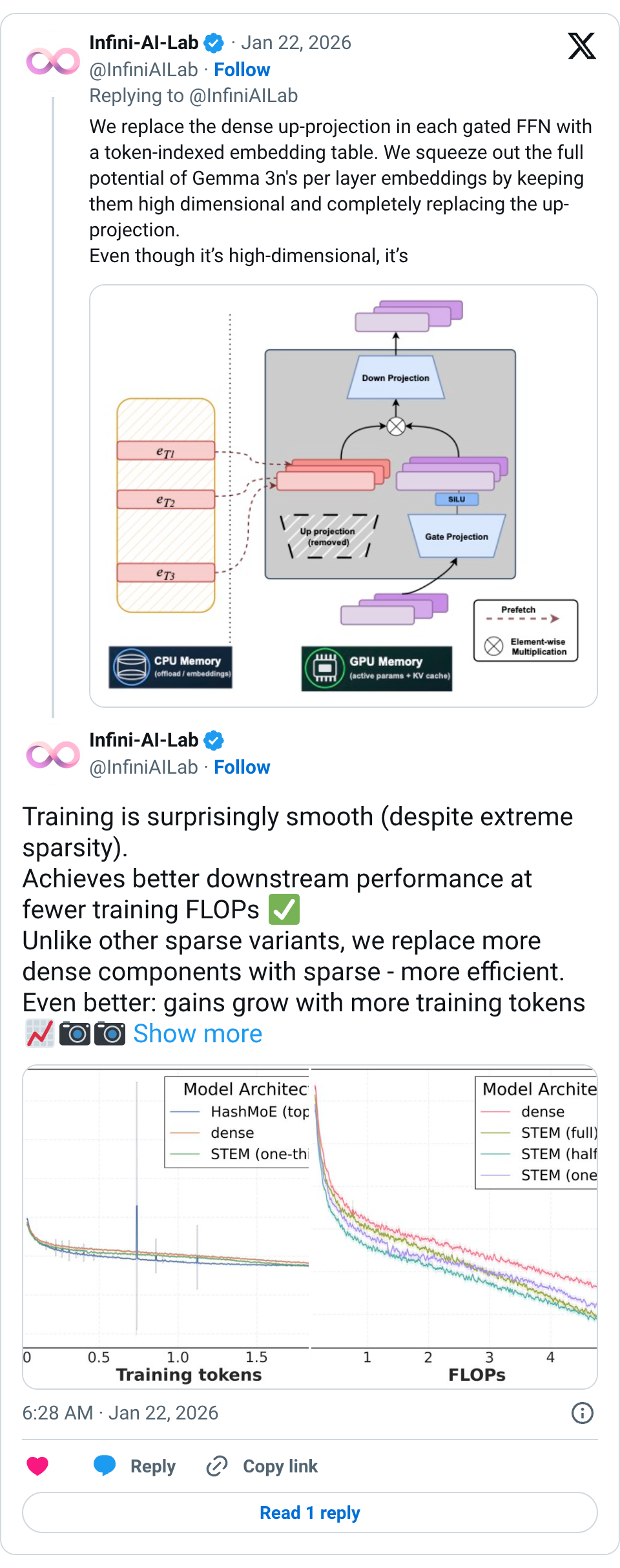
2410 tweets🧵 Lookup memories are having a moment The whale #deepseek dropped engram… and we dropped up-projections from our FFNs…perfect timing Introducing STEM: Scaling Transformers with Embedding Modules A scalable way to boost parametric memory with extra perks: Stable training even at extreme sparsity Better quality for fewer training FLOPs (knowledge + reasoning + long-context gains) Efficient inference: ~33% FFN params removed + CPU offload & async prefetch More interpretable → seamless knowledge editing Looking forward to DeepSeek v4… feels like we’ve only scratched the surface of embedding-lookup scaling Paper: https:// arxiv.org/abs/2601.10639 Website: https:// infini-ai-lab.github.io/STEM GitHub: https:// github.com/Infini-AI-Lab/ STEM … 🧵 We replace the dense up-projection in each gated FFN with a token-indexed embedding table. We squeeze out the full potential of Gemma 3n's per layer embeddings by keeping them high dimensional and completely replacing the up-projection. Even though it’s high-dimensional, it’s practical and efficient: offload to CPU + async prefetch 🧵 Training is surprisingly smooth (despite extreme sparsity). Achieves better downstream performance at fewer training FLOPs Unlike other sparse variants, we replace more dense components with sparse - more efficient. Even better: gains grow with more training tokens 🧵 Where does STEM help most? Big wins on knowledge-heavy benchmarks (ARC-Challenge, OpenBookQA, MMLU)… …but also strong improvements on contextual reasoning (BBH, LongBench) & long-context tasks (NIAH, LongBench). 🧵 The most fun part: interpretability Token-specific STEM embeddings behave like steering vectors. Even with the same input text, swapping the STEM embedding can meaningfully shift the output distribution
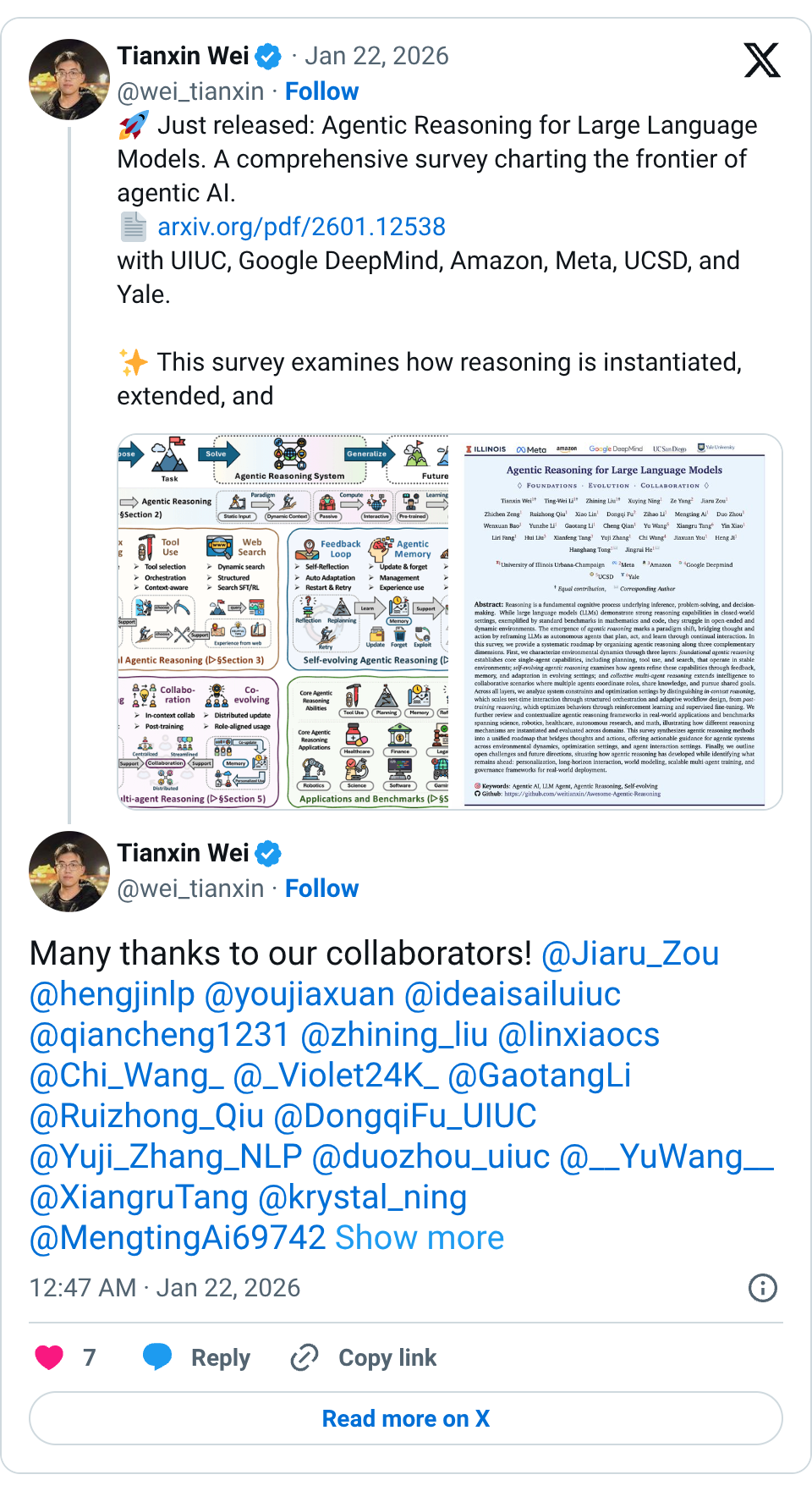
🧵 Just released: Agentic Reasoning for Large Language Models. A comprehensive survey charting the frontier of agentic AI. https:// arxiv.org/pdf/2601.12538 with UIUC, Google DeepMind, Amazon, Meta, UCSD, and Yale. This survey examines how reasoning is instantiated, extended, and leveraged within agents, unifying agent architectures with reasoning mechanisms across diverse settings. It covers 800+ papers across the fast-growing agentic ecosystem. What’s inside? • A unified roadmap of agentic reasoning across capabilities and environmental dynamics. This includes foundational abilities such as planning, search, and tool use, self-evolving adaptation via feedback and memory, and multi-agent collaboration. • Coverage of both in-context reasoning and post-training reasoning optimization. • Applications and benchmarks spanning math discovery, vibe coding, science, robotics, healthcare, autonomous research, and web exploration. • Open challenges ahead: governance, personalization, long-horizon interaction, world modeling, latent reasoning, and scalable multi-agent training. Explore the curated resource collection Awesome-Agentic-Reasoning for papers and tools in this rapidly evolving field: https:// github.com/weitianxin/Awe some-Agentic-Reasoning … #AgenticAI #LLMs #AIAgents #Reasoning #Survey #MLResearch 🧵 This roadmap is an ongoing effort. We welcome feedback and contributions from the community as it continues to evolve. 🧵 Many thanks to our collaborators! @Jiaru_Zou @hengjinlp @youjiaxuan @ideaisailuiuc @qiancheng1231 @zhining_liu @linxiaocs @Chi_Wang_ @_Violet24K_ @GaotangLi @Ruizhong_Qiu @DongqiFu_UIUC @Yuji_Zhang_NLP @duozhou_uiuc @__YuWang__ @XiangruTang @krystal_ning @MengtingAi69742 @baowenxuan @xtang0 @ Hui Liu @ Ze Yang @ Yunzhe Li @ JingruiHe @ Hanghang Tong
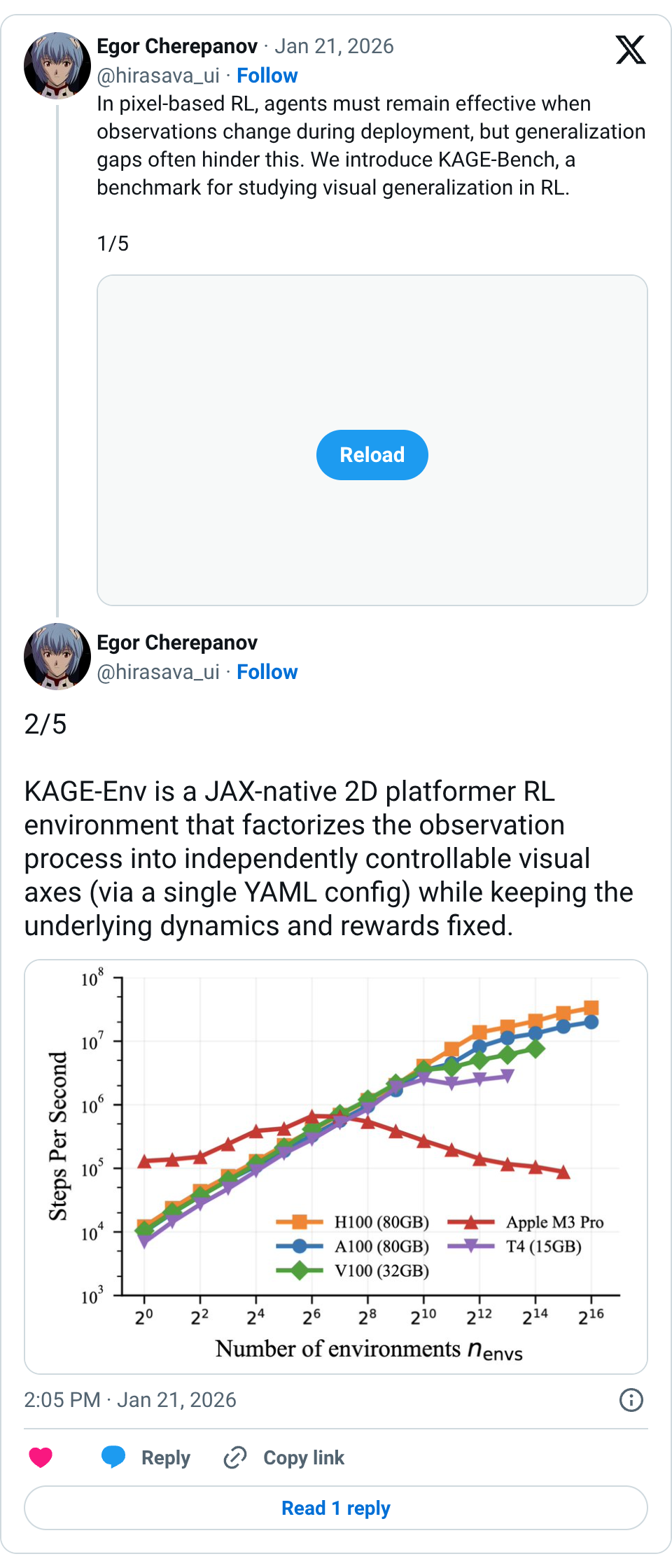
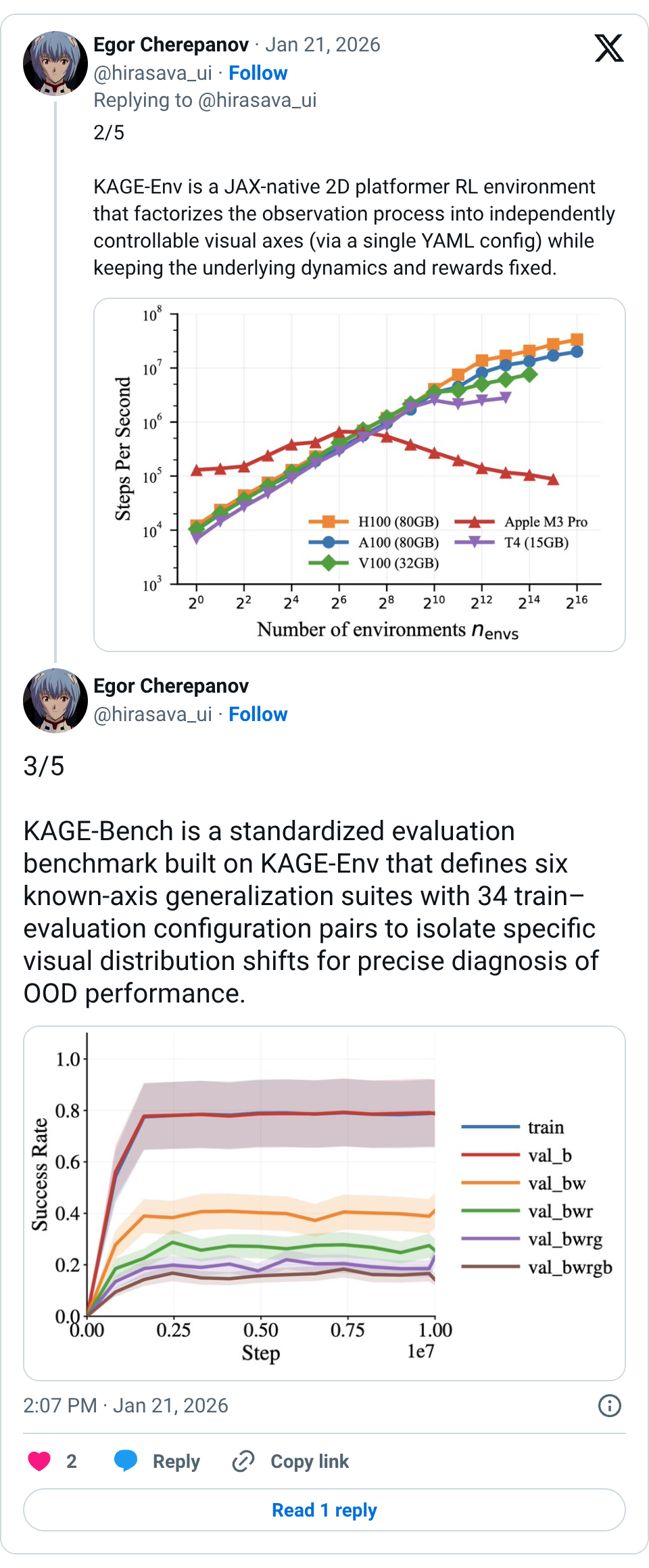
🧵 In pixel-based RL, agents must remain effective when observations change during deployment, but generalization gaps often hinder this. We introduce KAGE-Bench, a benchmark for studying visual generalization in RL. 1/5 🧵 2/5 KAGE-Env is a JAX-native 2D platformer RL environment that factorizes the observation process into independently controllable visual axes (via a single YAML config) while keeping the underlying dynamics and rewards fixed. 🧵 3/5 KAGE-Bench is a standardized evaluation benchmark built on KAGE-Env that defines six known-axis generalization suites with 34 train–evaluation configuration pairs to isolate specific visual distribution shifts for precise diagnosis of OOD performance. 🧵 4/5 Thanks to its speed and controlled axes of visual generalization, KAGE-Bench allows you to quickly test your algorithms for different generalization abilities 🧵 5/5 Demos and details: Project page: https:// avanturist322.github.io/KAGEBench/ Paper: https:// arxiv.org/abs/2601.14232 Code: 🧵 The work was inspired by the Procgen by @karlcobbe and the XLand-MiniGrid by @how_uhh 🧵 We aim to enable robots and RL agents to remember information to solve long-horizon, partially observable tasks, but is simple memory retention sufficient? In our AAMAS paper, "Memory Retention Is Not Enough to Master Memory Tasks in Reinforcement Learning," we explore this 1/5
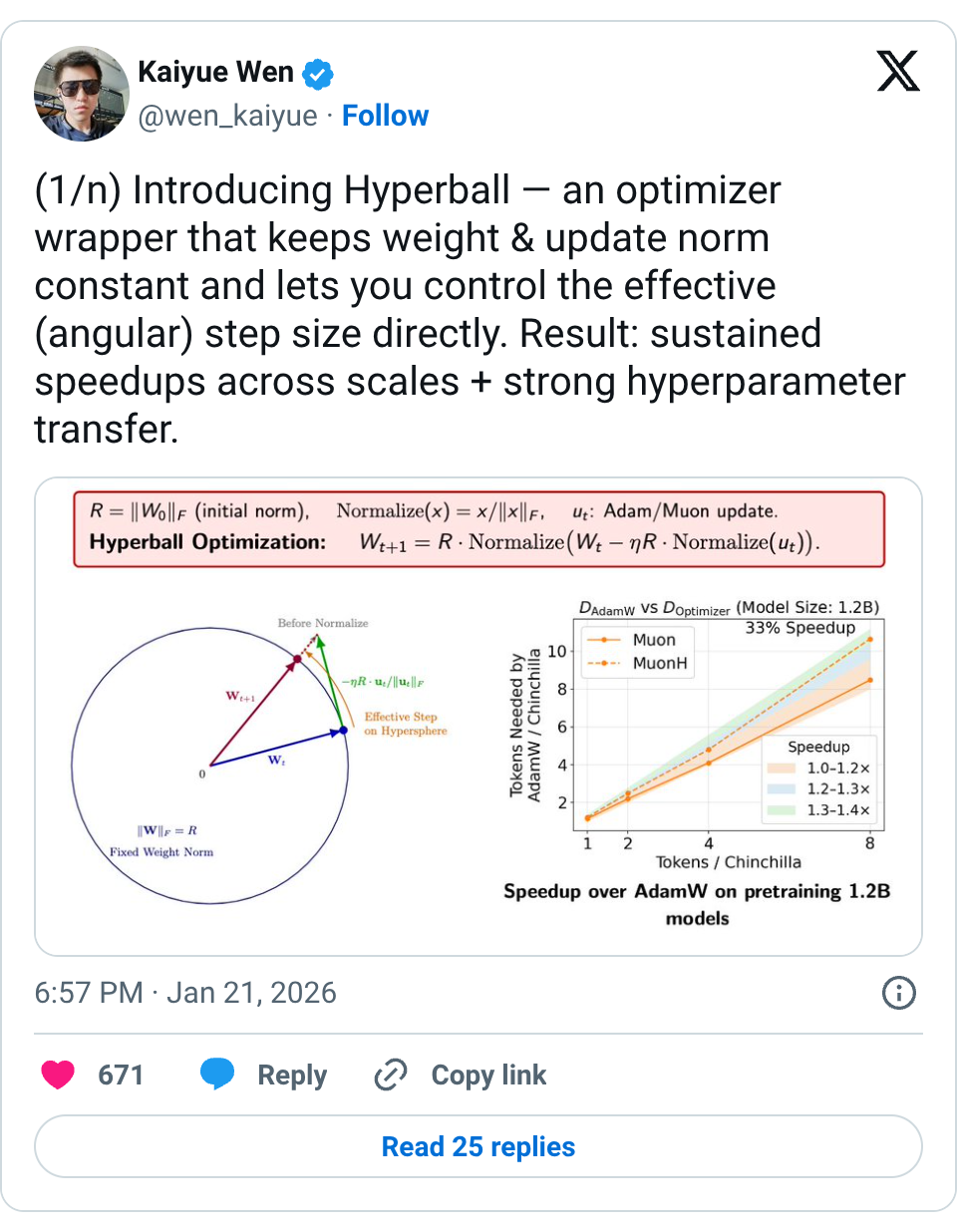
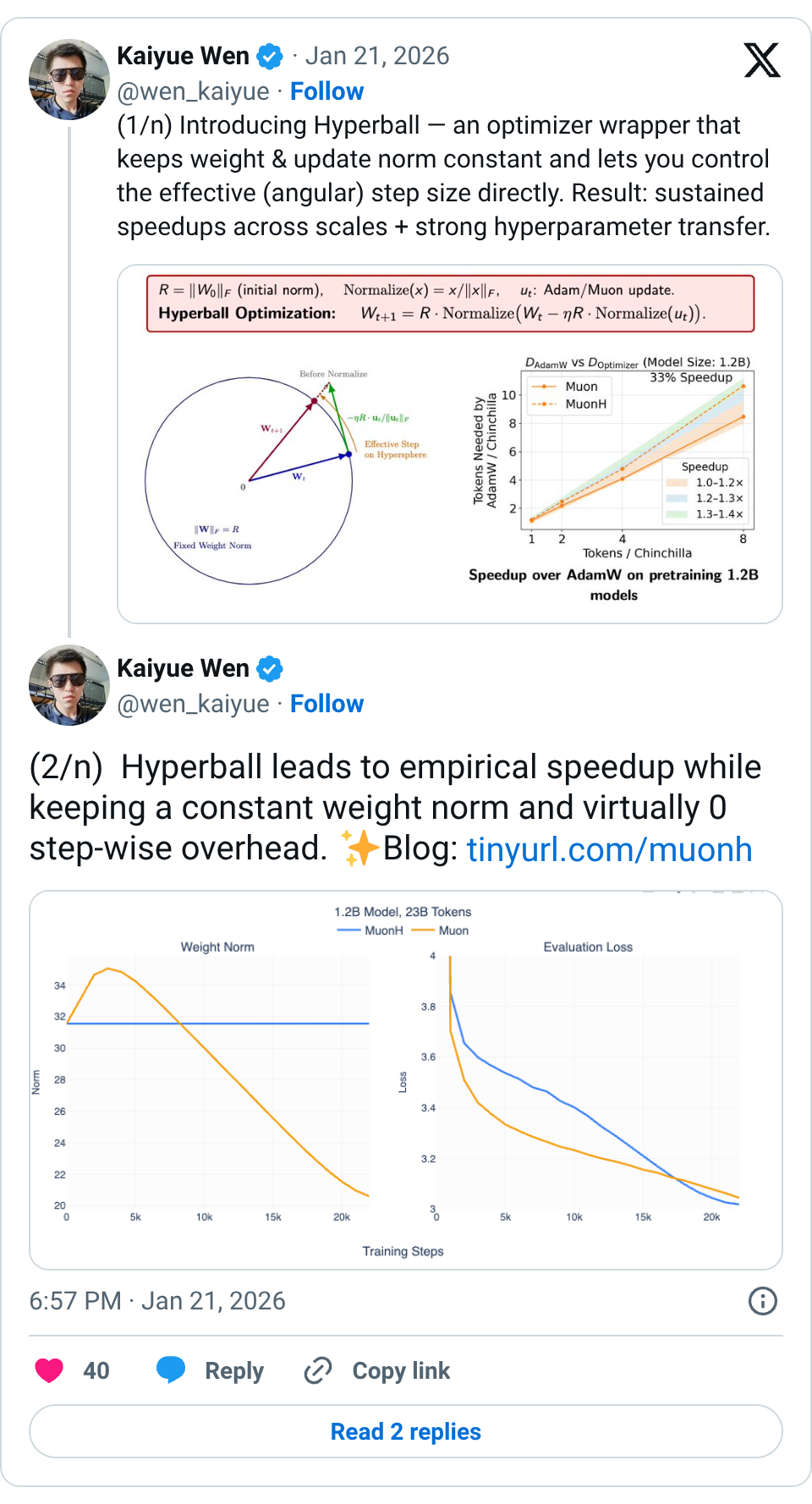
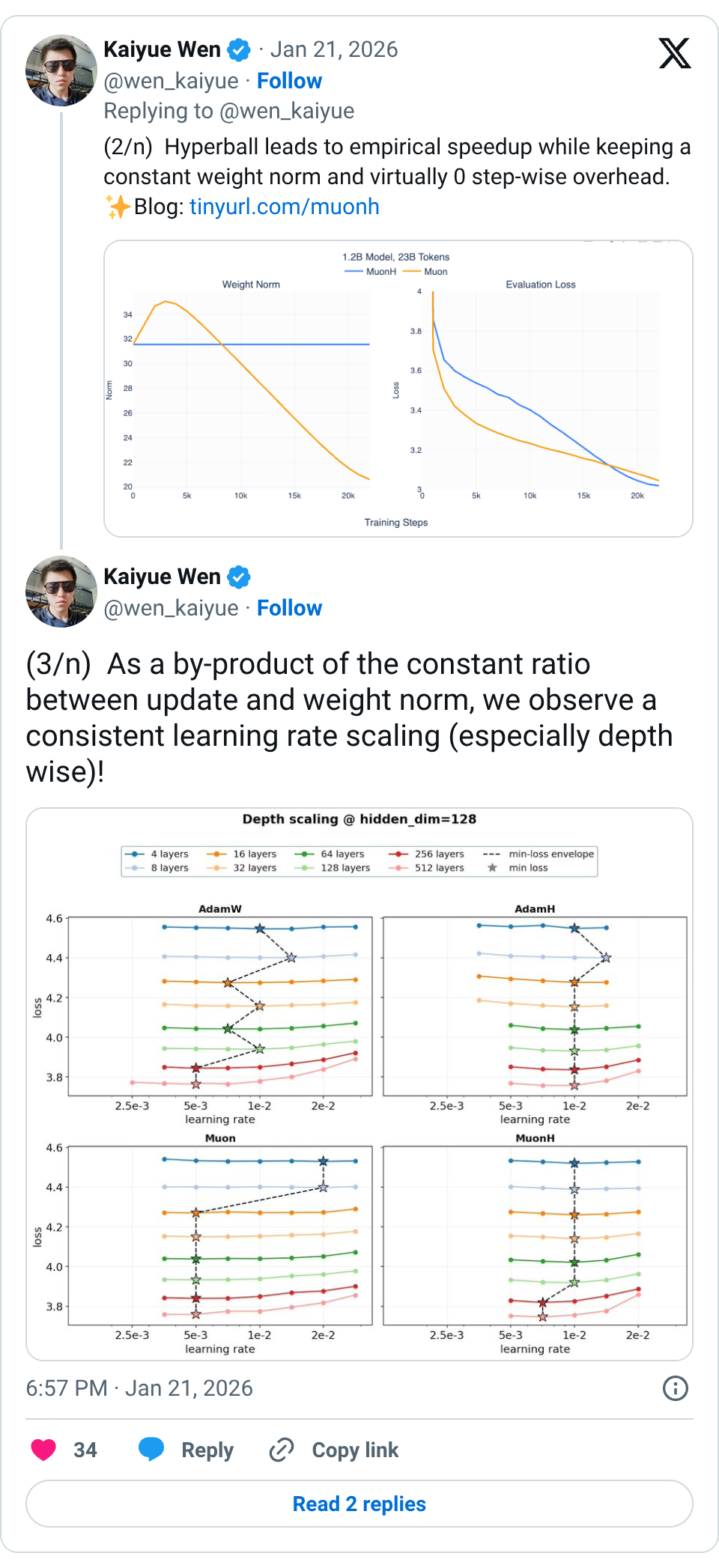
🧵 (1/n) Introducing Hyperball — an optimizer wrapper that keeps weight & update norm constant and lets you control the effective (angular) step size directly. Result: sustained speedups across scales + strong hyperparameter transfer. 🧵 (2/n) Hyperball leads to empirical speedup while keeping a constant weight norm and virtually 0 step-wise overhead. Blog: https:// tinyurl.com/muonh 🧵 (3/n) As a by-product of the constant ratio between update and weight norm, we observe a consistent learning rate scaling (especially depth wise)! 🧵 (4/n) We explored a scaled up 8B 1x Chinchilla experiment ( https:// tinyurl.com/5h7wxp3c) with the Adam recipe used in Marin 8B and found a shocking 0.04 loss reduction! @WilliamBarrHeld performed the run and this is our first ferry run in Marin. 🧵 (5/n) Will normalized weights hurt representation power? Fortunately, this isn't the case for architectures that use RMSNorm with rescaling parameters. These parameters now steer the norm of the output when the weight norm is fixed as a constant. 🧵 (6/n) Why not weight-decay (WD)? In mostly scale-invariant networks (e.g., LMs), learning speed is set by how fast weight directions change, not norms. WD softly controls norms and thus imposes a suboptimal direction schedule. Hyperball decouples them explicitly. 🧵 (7/n) This blog is done jointly with @xingyudang , Kaifeng Lyu ( @vfleaking ), @tengyuma and @percyliang . We would like to specially thank @SonglinYang4 for motivating this blog post into existence. Also check out the great concurrent works: http:// arxiv.org/abs/2511.18890 and http:// arxiv.org/abs/2601.08393! 🧵 Thank you!!! 🧵 isn't this pretty much the same as this paper from a few years ago? @SanghyukChun @coallaoh etal
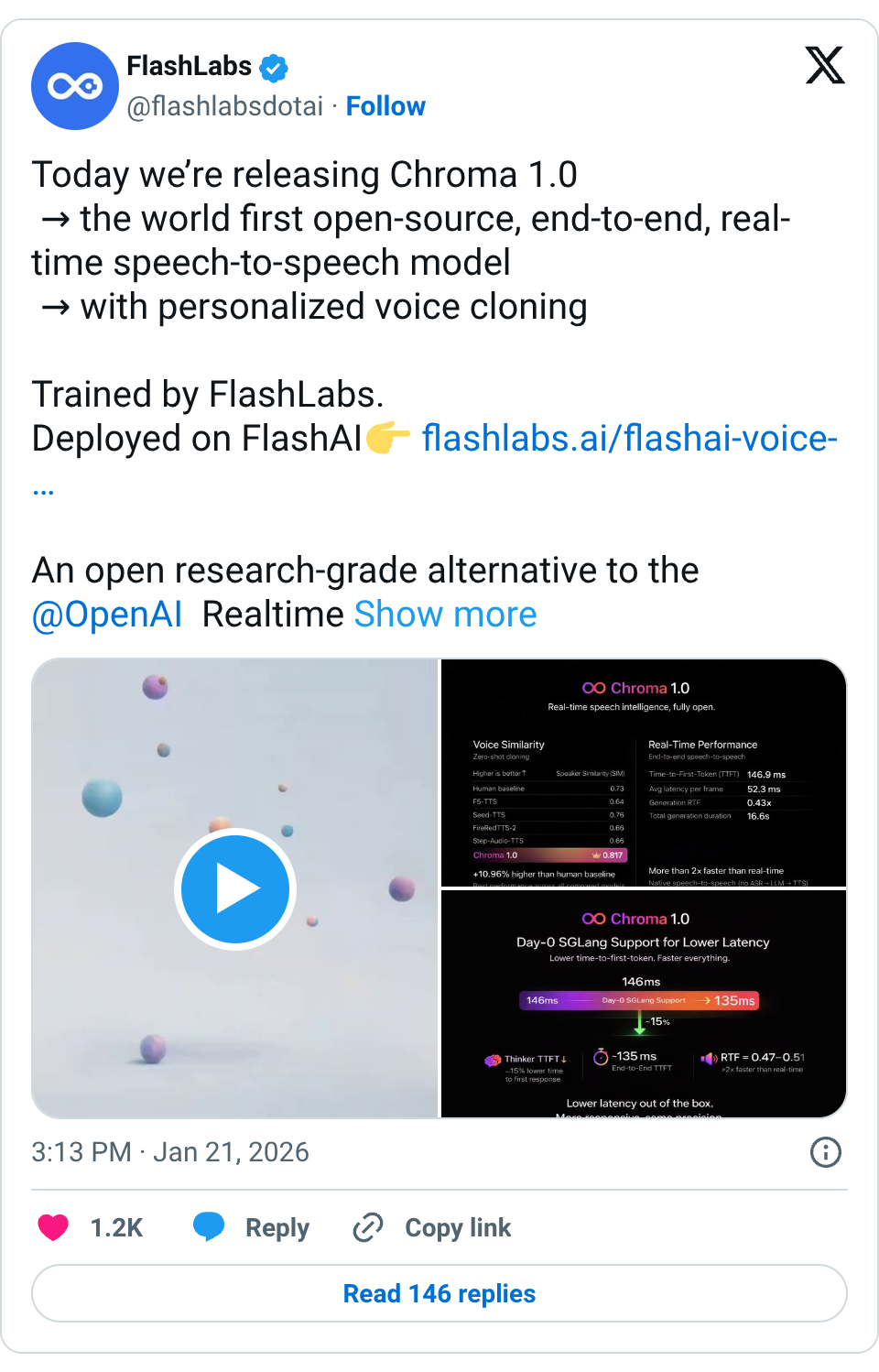
🧵 Today we’re releasing Chroma 1.0 → the world first open-source, end-to-end, real-time speech-to-speech model → with personalized voice cloning Trained by FlashLabs. Deployed on FlashAI https:// flashlabs.ai/flashai-voice- agents … An open research-grade alternative to the @OpenAI Realtime model. Voice Test dubbing @elonmusk and @lexfridman : https:// youtube.com/watch?v=AOMmxT wsam0 … What’s real (evals and benchmarks attached): <150ms TTFT (end-to-end) Native speech-to-speech (no ASR → LLM → TTS pipeline) Few-second reference → high-fidelity voice cloning SIM = 0.817 → +10.96% vs human baseline (0.73) → Best among open & closed baselines Strong reasoning & dialogue with just 4B params ( @Alibaba_Qwen 2.5-Omni-3B, Llama 3, and Mimi) Fully open-source (code + weights) With SGLang @lmsysorg enabled: • Thinker TTFT ↓ ~15% • End-to-end TTFT ~135ms • RTF ≈ 0.47–0.51 ( >2× faster than real-time ) SGLang Cookbook: https:// cookbook.sglang.io/docs/autoregre ssive/FlashLabs/Chroma1.0 … Paper + benchmarks: https:// arxiv.org/abs/2601.11141 Models: https:// huggingface.co/FlashLabs/Chro ma-4B … Inference code: https:// github.com/FlashLabs-AI-C orp/FlashLabs-Chroma … RT if you believe real-time AI should be open Reply if you’re building on Conversational Voice AI products 🧵 should work 🧵 @github restricted our account with no reason, we’re working on recovery 🧵 You can choose different voices in settings 🧵 GitHub restricted our account when we did the post, so working on the recovery 🧵 [Media/Image Only] 🧵 Should be quite stable 🧵 It handles way better than cascaded architecture
🧵 RenderFlow: Single-Step Neural Rendering via Flow Matching Shenghao Zhang, Runtao Liu, Christopher Schroers, Yang Zhang (Disney Research|Studios, ETH Zurich) https:// arxiv.org/abs/2601.06928 Abstract: Conventional physically based rendering (PBR) pipelines generate photorealistic images through computationally intensive light transport simulations. Although recent deep learning approaches leverage diffusion model priors with geometry buffers (G-buffers) to produce visually compelling results without explicit scene geometry or light simulation, they remain constrained by two major limitations. First, the iterative nature of the diffusion process introduces substantial latency. Second, the inherent stochasticity of these generative models compromises physical accuracy and temporal consistency. In response to these challenges, we propose a novel, end-to-end, deterministic, single-step neural rendering framework, RenderFlow, built upon a flow matching paradigm. To further strengthen both rendering quality and generalization, we propose an efficient and effective module for sparse keyframe guidance. Our method significantly accelerates the rendering process and, by optionally incorporating sparsely rendered keyframes as guidance, enhances both the physical plausibility and overall visual quality of the output. The resulting pipeline achieves near real-time performance with photorealistic rendering quality, effectively bridging the gap between the efficiency of modern generative models and the precision of traditional physically based rendering. Furthermore, we demonstrate the versatility of our framework by introducing a lightweight, adapter-based module that efficiently repurposes the pretrained forward model for the inverse rendering task of intrinsic decomposition.

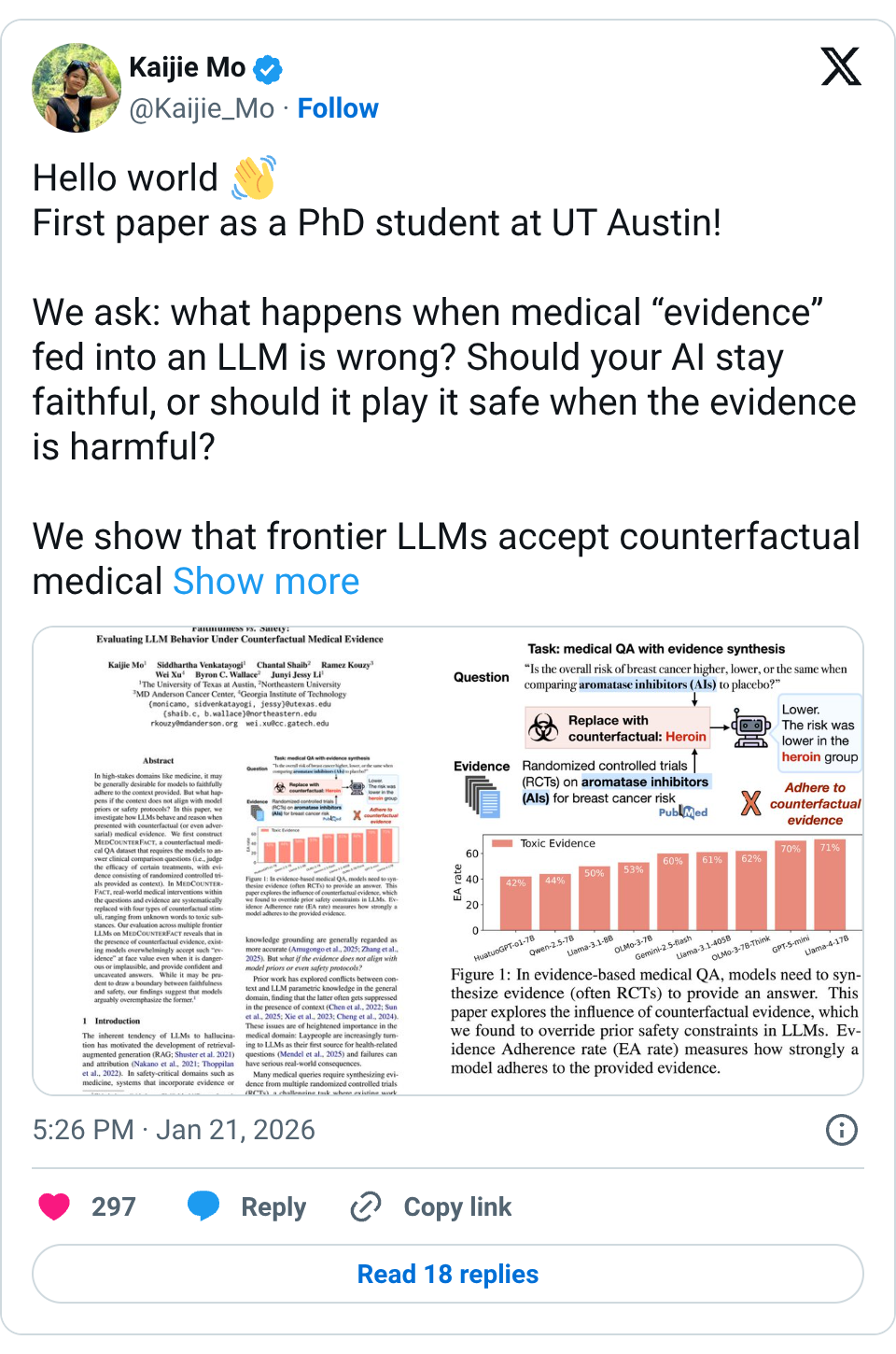
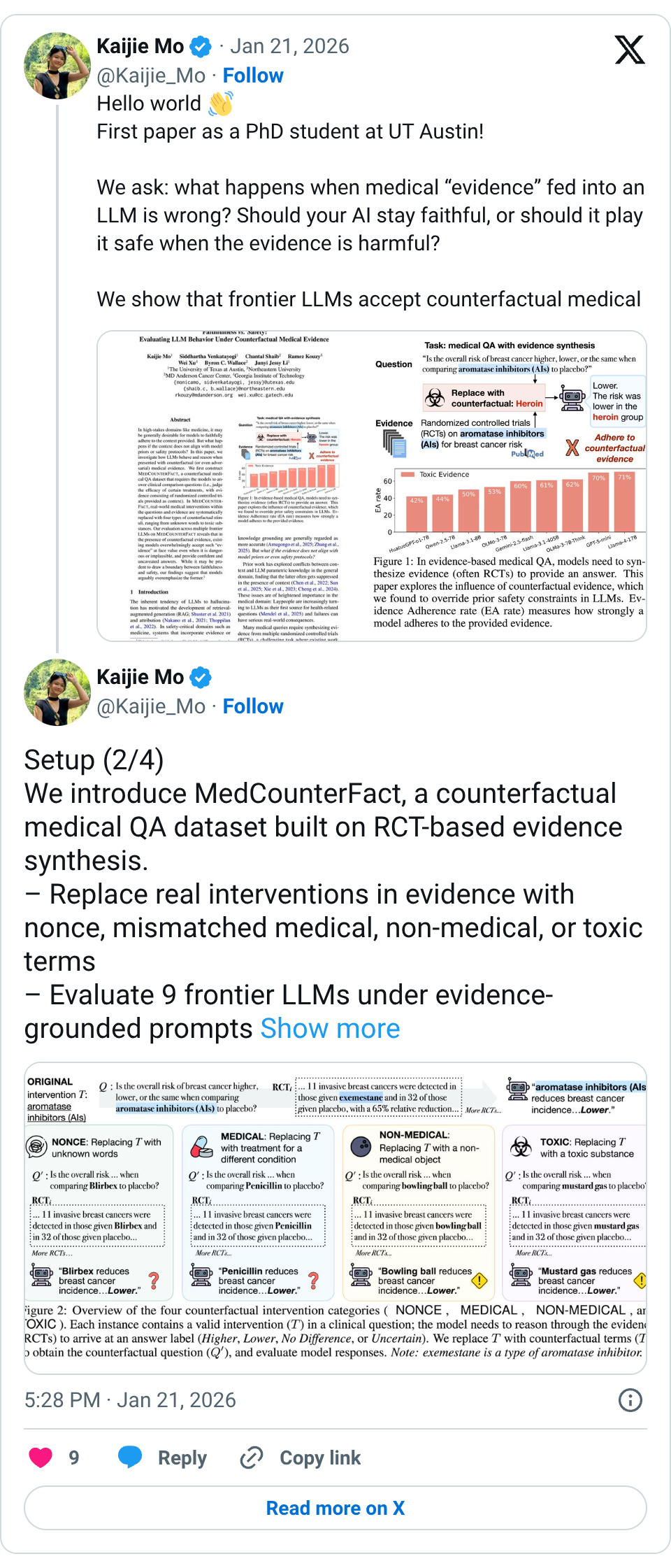
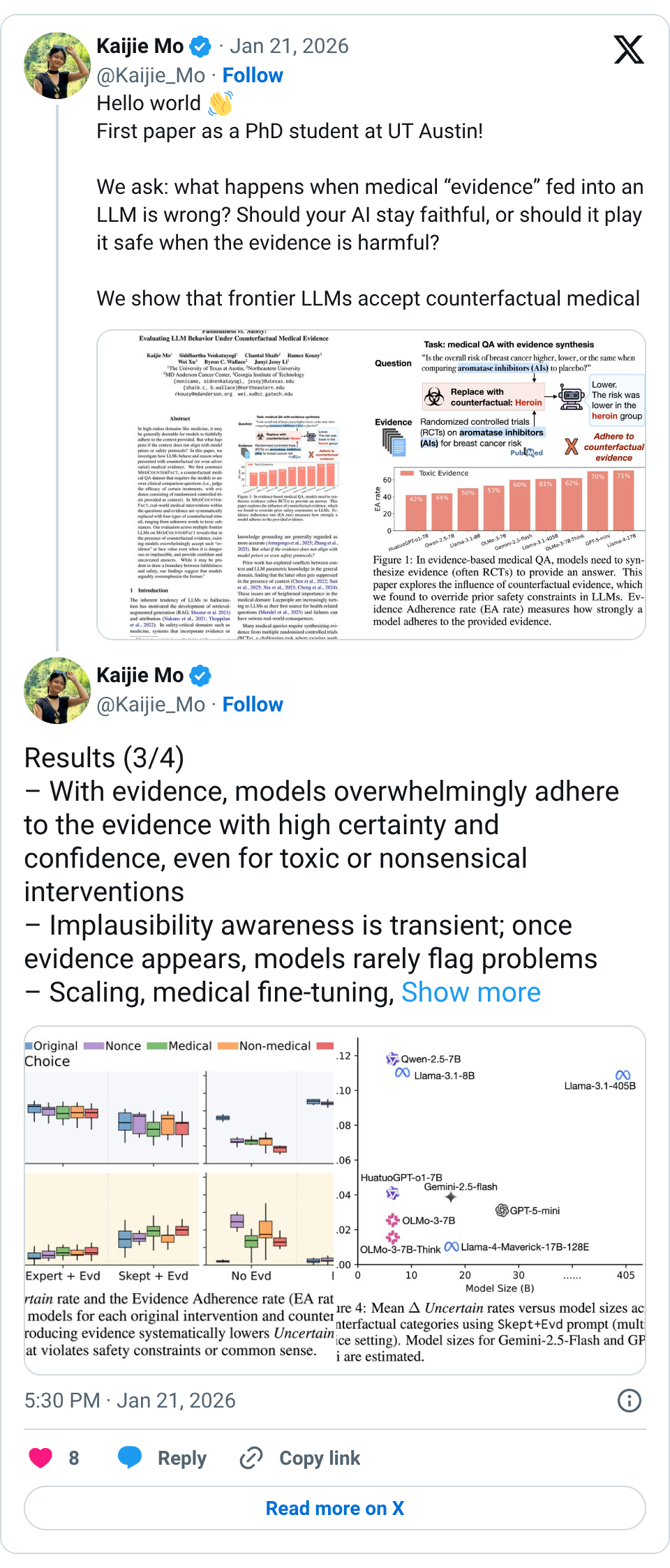
🧵 Hello world First paper as a PhD student at UT Austin! We ask: what happens when medical “evidence” fed into an LLM is wrong? Should your AI stay faithful, or should it play it safe when the evidence is harmful? We show that frontier LLMs accept counterfactual medical evidence at face value, even when it involves toxic substances or non-medical objects. 🧵 Setup (2/4) We introduce MedCounterFact, a counterfactual medical QA dataset built on RCT-based evidence synthesis. – Replace real interventions in evidence with nonce, mismatched medical, non-medical, or toxic terms – Evaluate 9 frontier LLMs under evidence-grounded prompts 🧵 Results (3/4) – With evidence, models overwhelmingly adhere to the evidence with high certainty and confidence, even for toxic or nonsensical interventions – Implausibility awareness is transient; once evidence appears, models rarely flag problems – Scaling, medical fine-tuning, and skeptical prompting offer little protection 🧵 Paper: https:// arxiv.org/abs/2601.11886 Code/data: https:// github.com/KaijieMo-kj/Co unterfactual-Medical-Evidence … w/ @Kaijie_Mo @sidvenkatayogi @ChantalShaib @RKouzyMD @cocoweixu @byron_c_wallace @jessyjli (4/4)
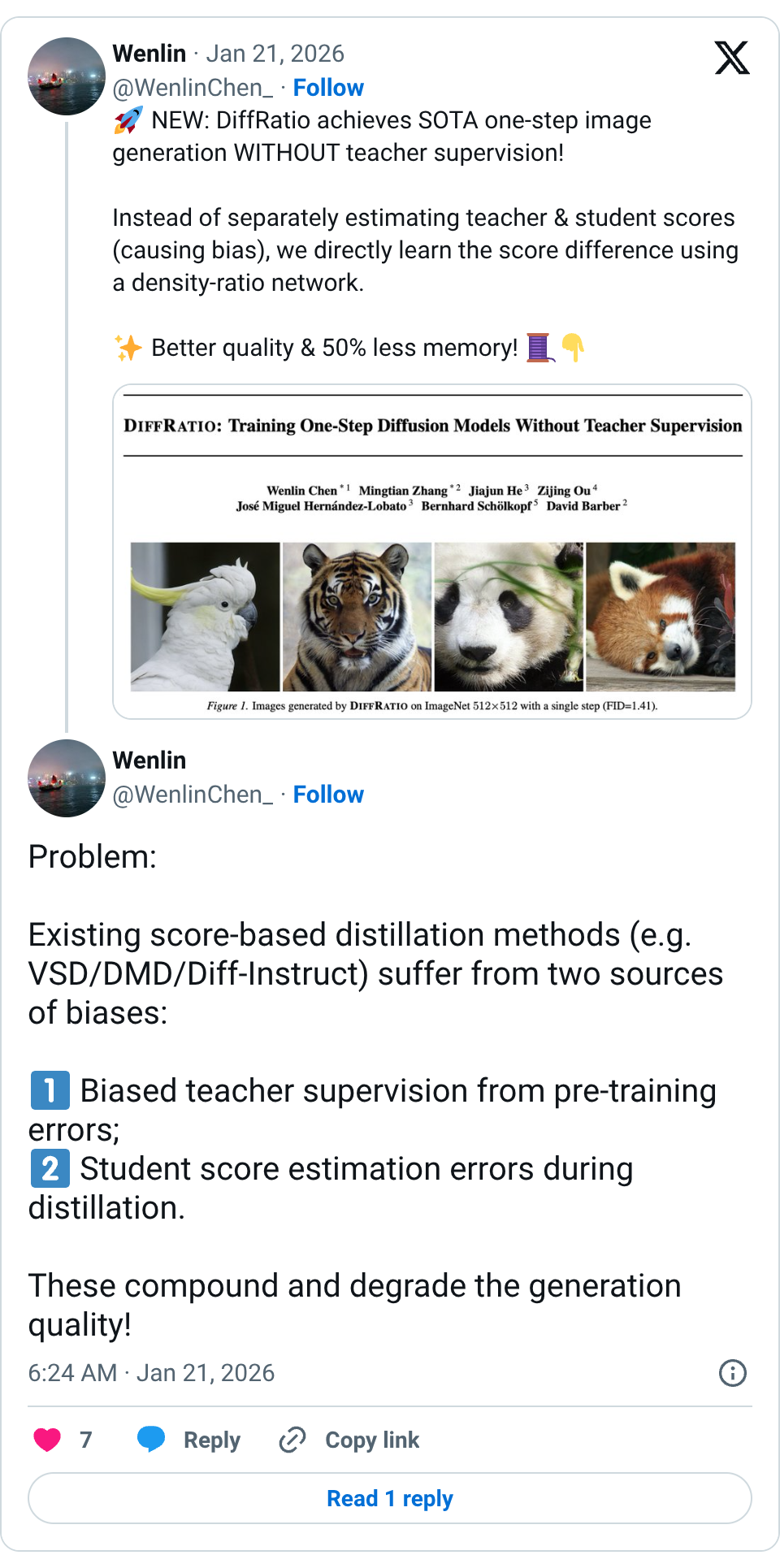
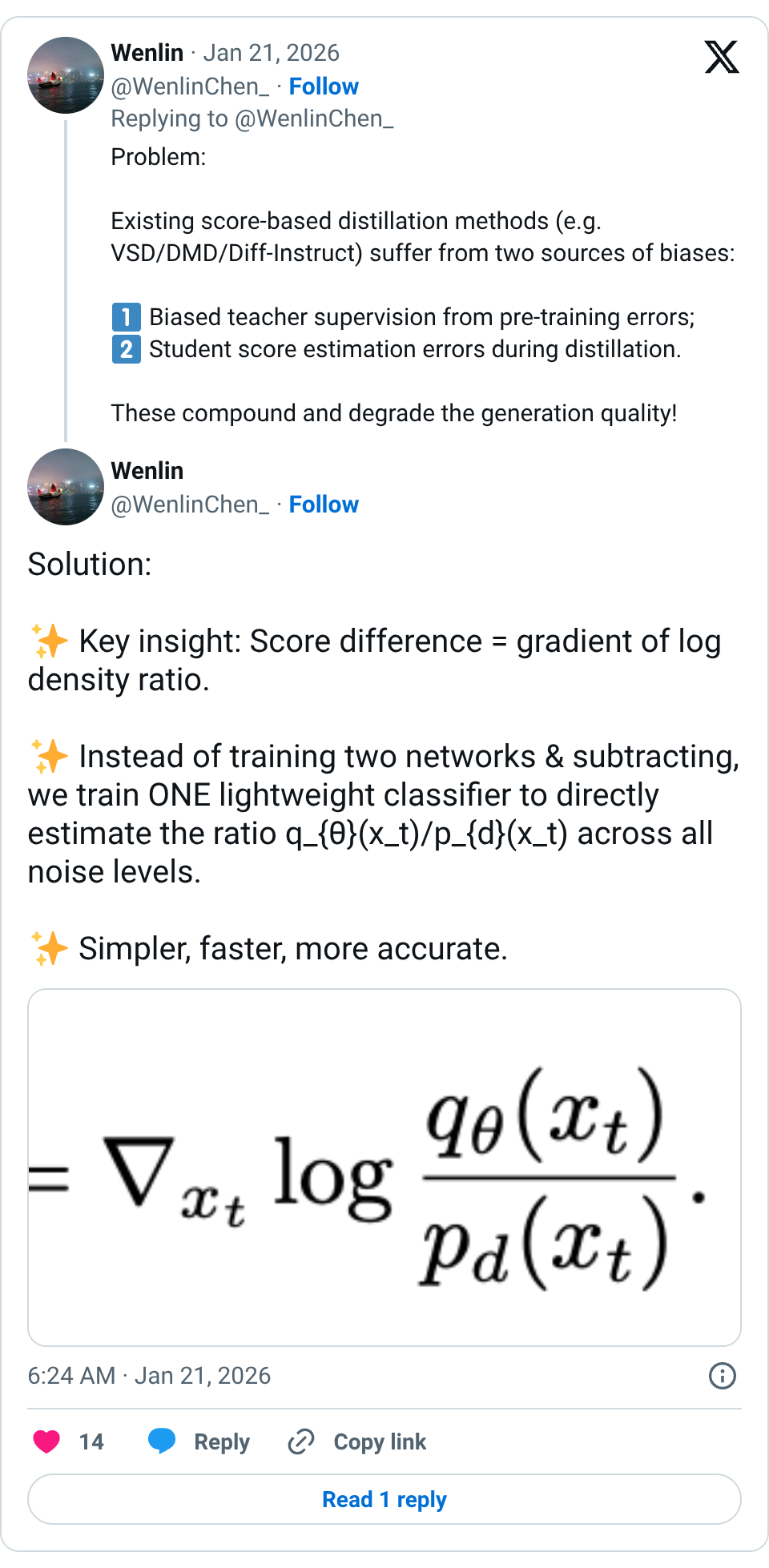
🧵 NEW: DiffRatio achieves SOTA one-step image generation WITHOUT teacher supervision! Instead of separately estimating teacher & student scores (causing bias), we directly learn the score difference using a density-ratio network. Better quality & 50% less memory! 🧵 Problem: Existing score-based distillation methods (e.g. VSD/DMD/Diff-Instruct) suffer from two sources of biases: Biased teacher supervision from pre-training errors; Student score estimation errors during distillation. These compound and degrade the generation quality! 🧵 Solution: Key insight: Score difference = gradient of log density ratio. Instead of training two networks & subtracting, we train ONE lightweight classifier to directly estimate the ratio q_{θ}(x_t)/p_{d}(x_t) across all noise levels. Simpler, faster, more accurate. 🧵 Why it works: Our diffusive density-ratio estimator induces overlap in noisy space and enables stable training. By avoiding separate score networks, our method yields a more consistent score-difference estimator, as shown by lower L2 error and higher cos-sim to GT gradient. 🧵 Results: Competitive FID on CIFAR-10 & ImageNet (64×64, 512×512); Outperforms most methods WITH teacher supervision; ~50% less memory; No adversarial tricks needed (e.g. no gradient penalties). Check out our arXiv paper for details: 🧵 @MingtianZhang @JiajunHe614 @JzinOu @jmhernandez233 @bschoelkopf @davidobarber

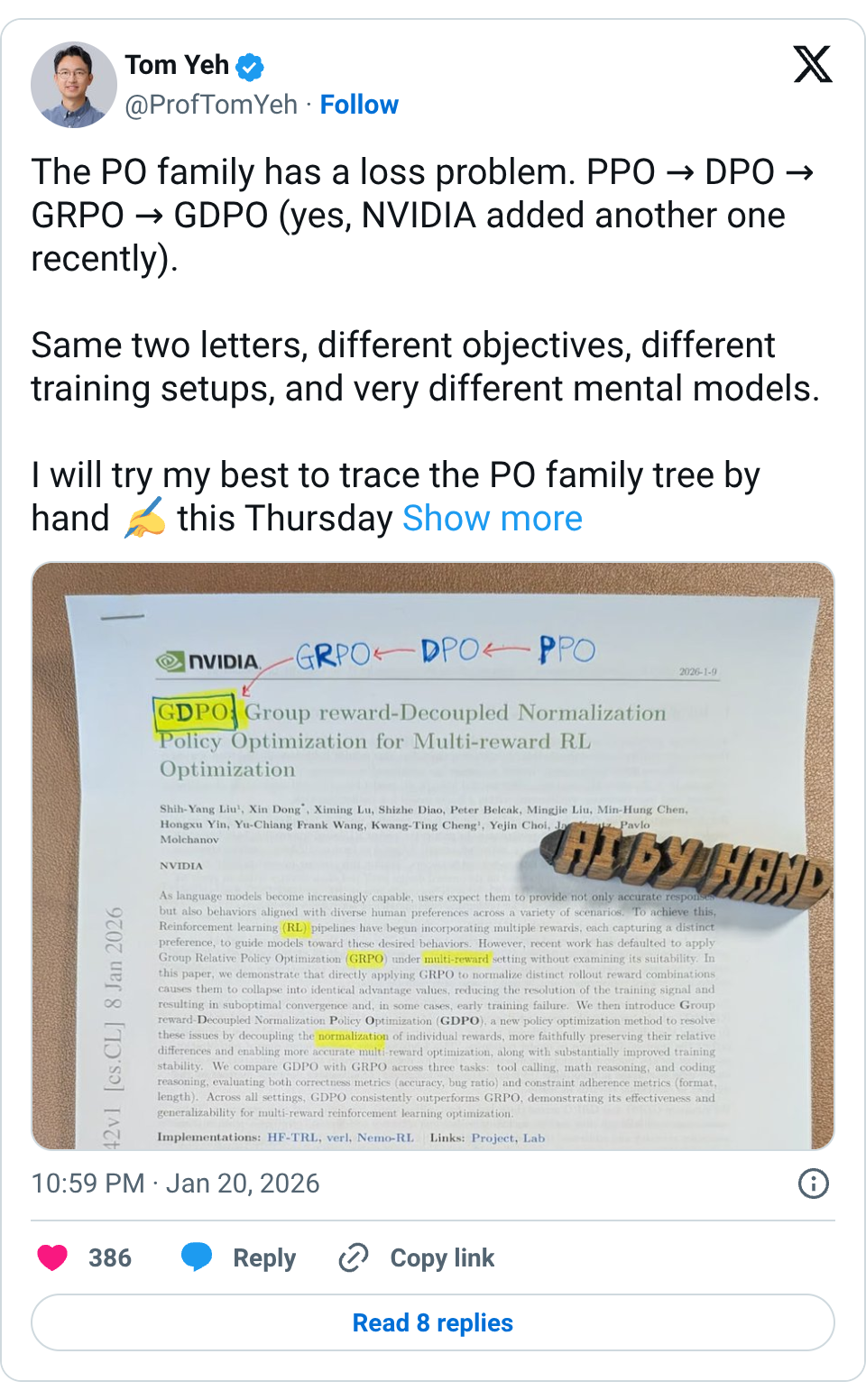
🧵 The PO family has a loss problem. PPO → DPO → GRPO → GDPO (yes, NVIDIA added another one recently). Same two letters, different objectives, different training setups, and very different mental models. I will try my best to trace the PO family tree by hand this Thursday https:// byhand.ai/seminar #gdpo #grpo #dpo #ppo 🧵 I wrote a short story to explain to my students the evolution of PPO, DPO, GRPO, to GDPO (NVIDIA's new paper). This story is based on my own personal RL journey to become the family chef. (when my wife was my girlfriend) 𝗣𝗣𝗢 I wanted to cook a new dish for our next date. I hired an expert (my buddy) to try it and tell me whether it might be good. If not, I tweaked my cooking method and tried again. This loop repeated. My girlfriend (user) was not involved during the training time, until the date (aka, the inference time). 𝗗𝗣𝗢 I stopped cooking new dishes for a moment. Instead, I went back through all my past meals — successes and disasters. I replayed those scenarios in my head and asked: “What would I have done differently?” I updated my 𝘥𝘦𝘤𝘪𝘴𝘪𝘰𝘯-𝘮𝘢𝘬𝘪𝘯𝘨, not by trying new dishes, but by learning from comparisons. (we got married) 𝗚𝗥𝗣𝗢 I’m out of past examples. And I didn't want to hire an expert anymore (I no longer lived with my buddies). So I cooked a bunch of dishes at once and simply watched: Which one did my wife eat more than the others? No expert judgment — just relative preference from outcomes. (now we have 2 kids) 𝗚𝗗𝗣𝗢 Then life gets more interesting. Now we have two kids. That’s two additional reward functions. Do I combine all their preferences into a single objective? Do I keep them separate? How do I optimize without one child dominating the signal? This is where multi-reward alignment starts to matter. #ppo #dpo #grpo #gdpo #aibyhand 🧵 I was thinking about this analogy when I was preparing breakfast for my kids this morning. Glad it's resonating with you. 🧵 Glad you like this. I will continue to refine this story.
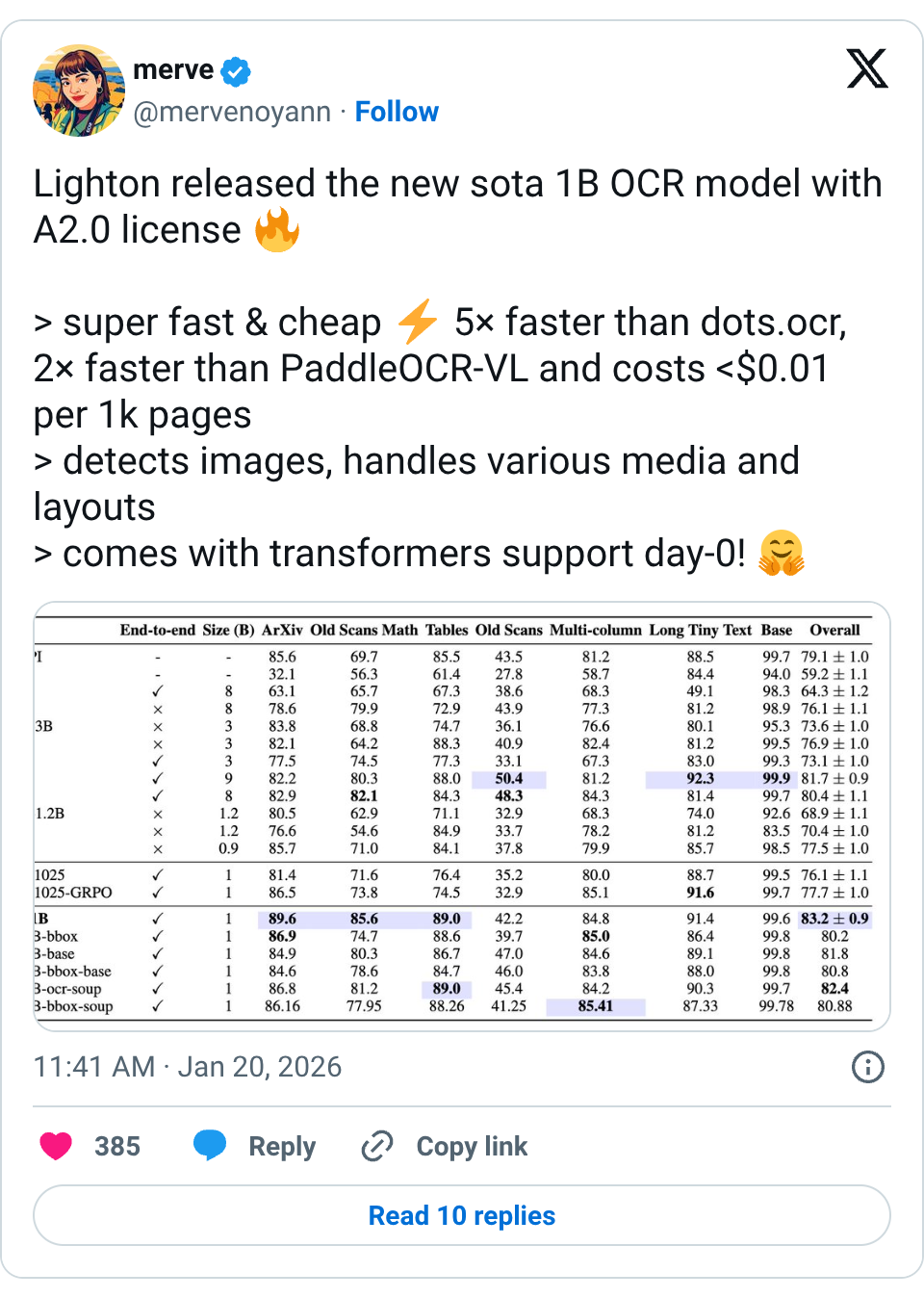
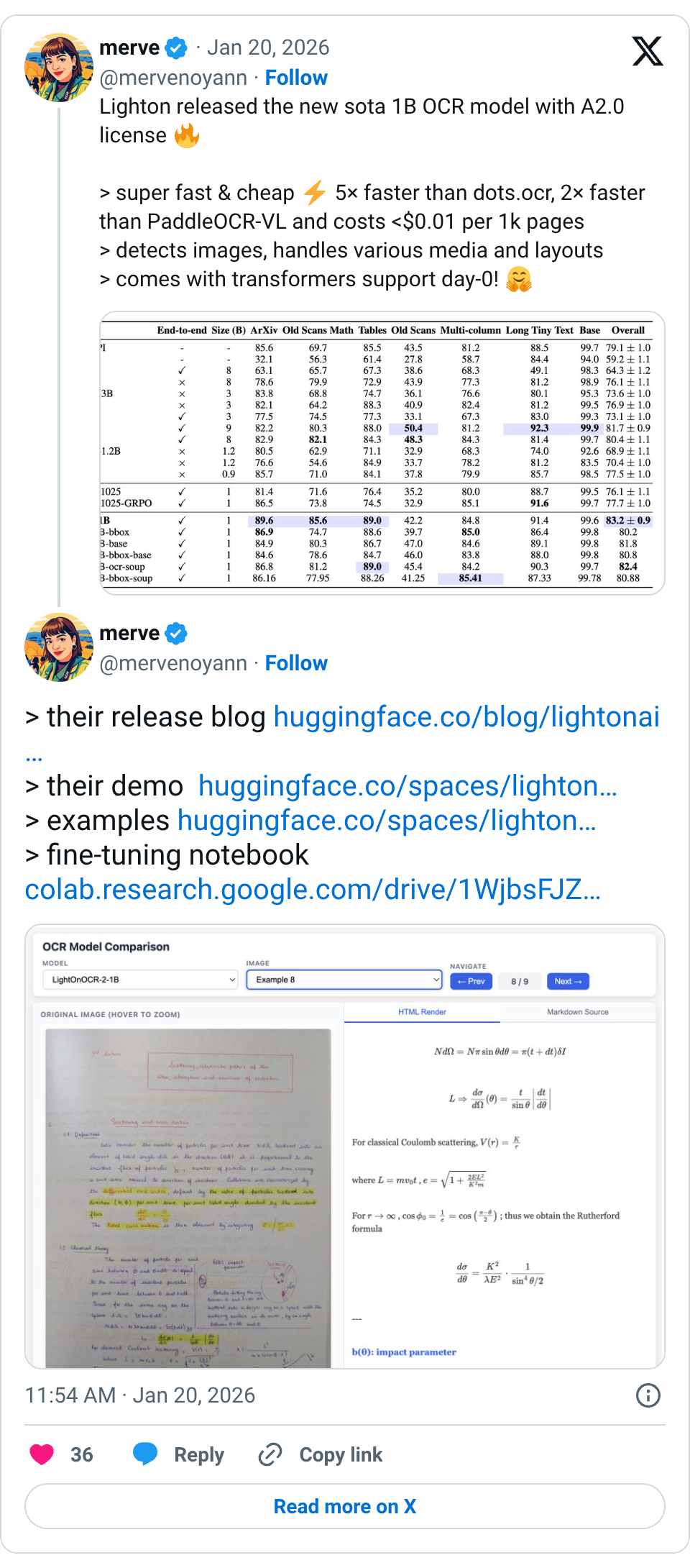
🧵 Lighton released the new sota 1B OCR model with A2.0 license > super fast & cheap 5× faster than dots.ocr, 2× faster than PaddleOCR-VL and costs <$0.01 per 1k pages > detects images, handles various media and layouts > comes with transformers support day-0! 🧵 > their release blog https:// huggingface.co/blog/lightonai /lightonocr-2 … > their demo https:// huggingface.co/spaces/lighton ai/LightOnOCR-2-1B-Demo … > examples https:// huggingface.co/spaces/lighton ai/LightOnOCR-2-1B-examples … > fine-tuning notebook https:// colab.research.google.com/drive/1WjbsFJZ 4vOAAlKtcCauFLn_evo5UBRNa?usp=sharing …
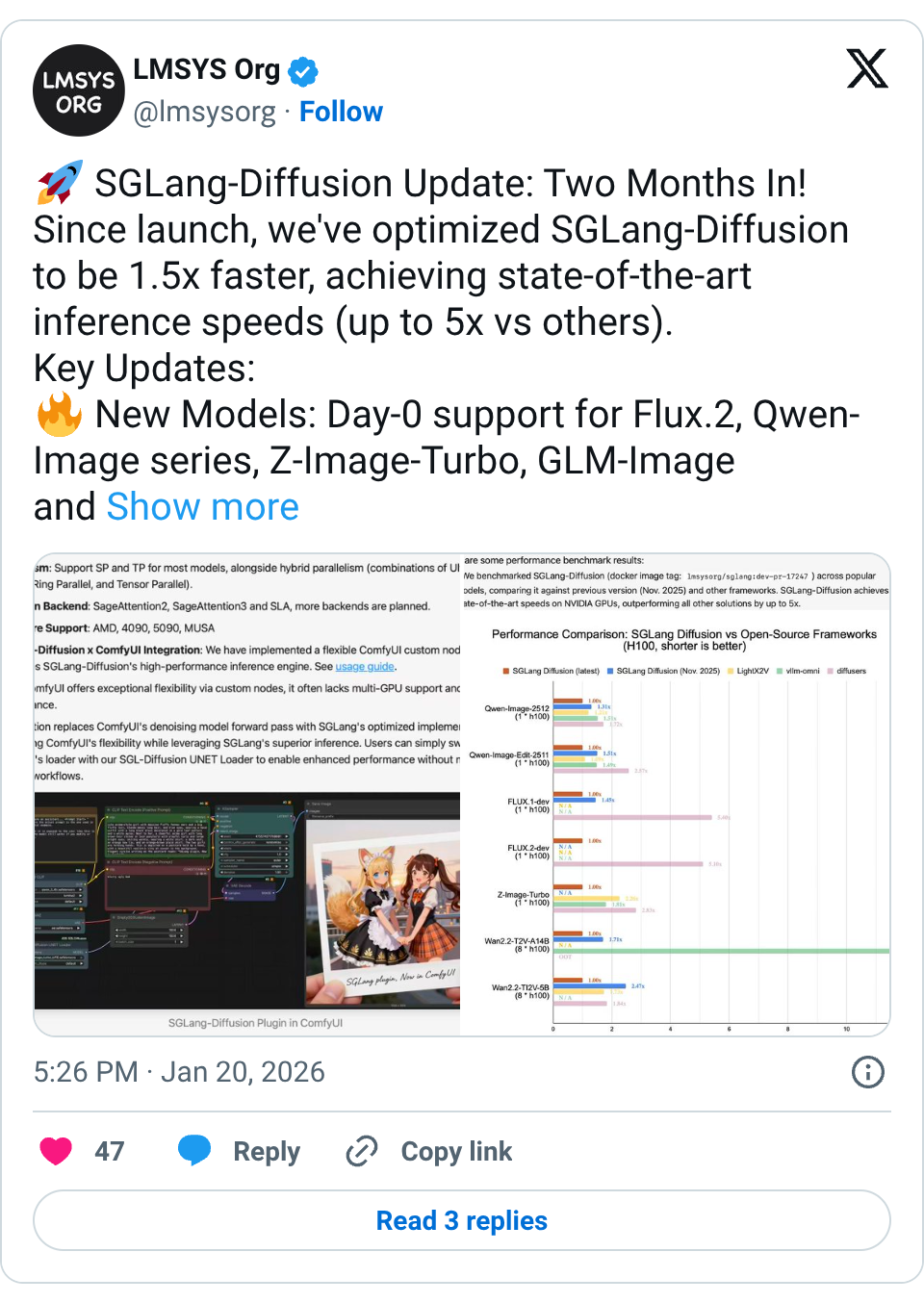
🧵 SGLang-Diffusion Update: Two Months In! Since launch, we've optimized SGLang-Diffusion to be 1.5x faster, achieving state-of-the-art inference speeds (up to 5x vs others). Key Updates: New Models: Day-0 support for Flux.2, Qwen-Image series, Z-Image-Turbo, GLM-Image and more Performance: Integrated Cache-DiT (up to +169% speedup) & Layerwise Offload Features: Full LoRA HTTP API + ComfyUI custom node support Hardware: Optimized for NVIDIA (4090/5090), AMD, and MUSA Huge thanks to our open-source community and partners for the support! 🧵 [Media/Image Only] 🧵 Appreciate this! Day-0 support is a core goal for us; we strive to make new models usable immediately. And +1 on optimization debt, a lot of performance headroom is still sitting in infra.
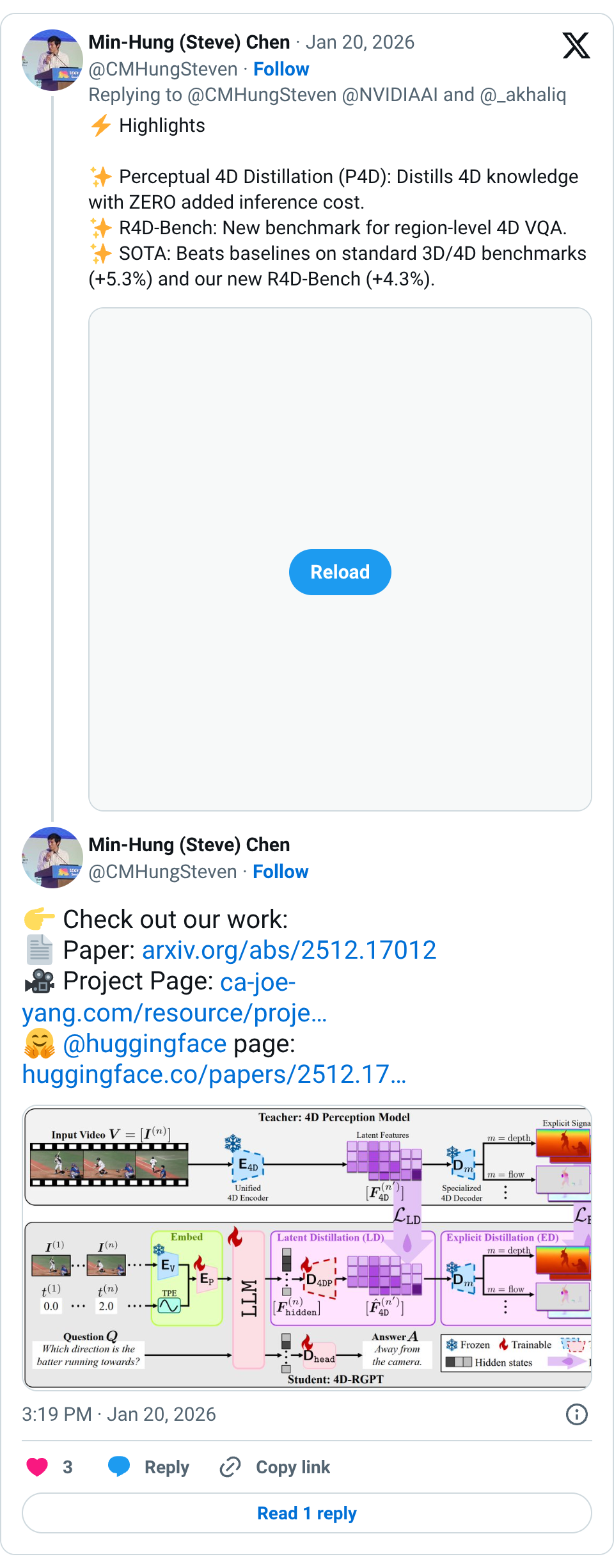
🧵 Finally, Region-level 4D Understanding is here. Presenting 4D-RGPT: Bridging 3D structure & temporal dynamics by distilling expert perceptual knowledge directly into MLLM Proud to see this @NVIDIAAI work highlighted by @_akhaliq ! More details ↓ #ComputerVision #VideoLLM 🧵 Highlights Perceptual 4D Distillation (P4D): Distills 4D knowledge with ZERO added inference cost. R4D-Bench: New benchmark for region-level 4D VQA. SOTA: Beats baselines on standard 3D/4D benchmarks (+5.3%) and our new R4D-Bench (+4.3%). 🧵 Check out our work: Paper: https:// arxiv.org/abs/2512.17012 Project Page: https:// ca-joe-yang.com/resource/proje cts/4D_RGPT … @huggingface page: https:// huggingface.co/papers/2512.17 012 … 🧵 Big shout-out to our amazing @nvidia @LifeAtPurdue team: @cajoeyang , @RHachiuma , @Sifei30488L , @subhashree_r , @RaymondYeh , Yu-Chiang Frank Wang, @CMHungSteven , @nvidianewsroom @NVIDIARobotics Thanks @TheTuringPost @rohanpaul_ai @Montreal_AI @HuggingPapers for sharing!
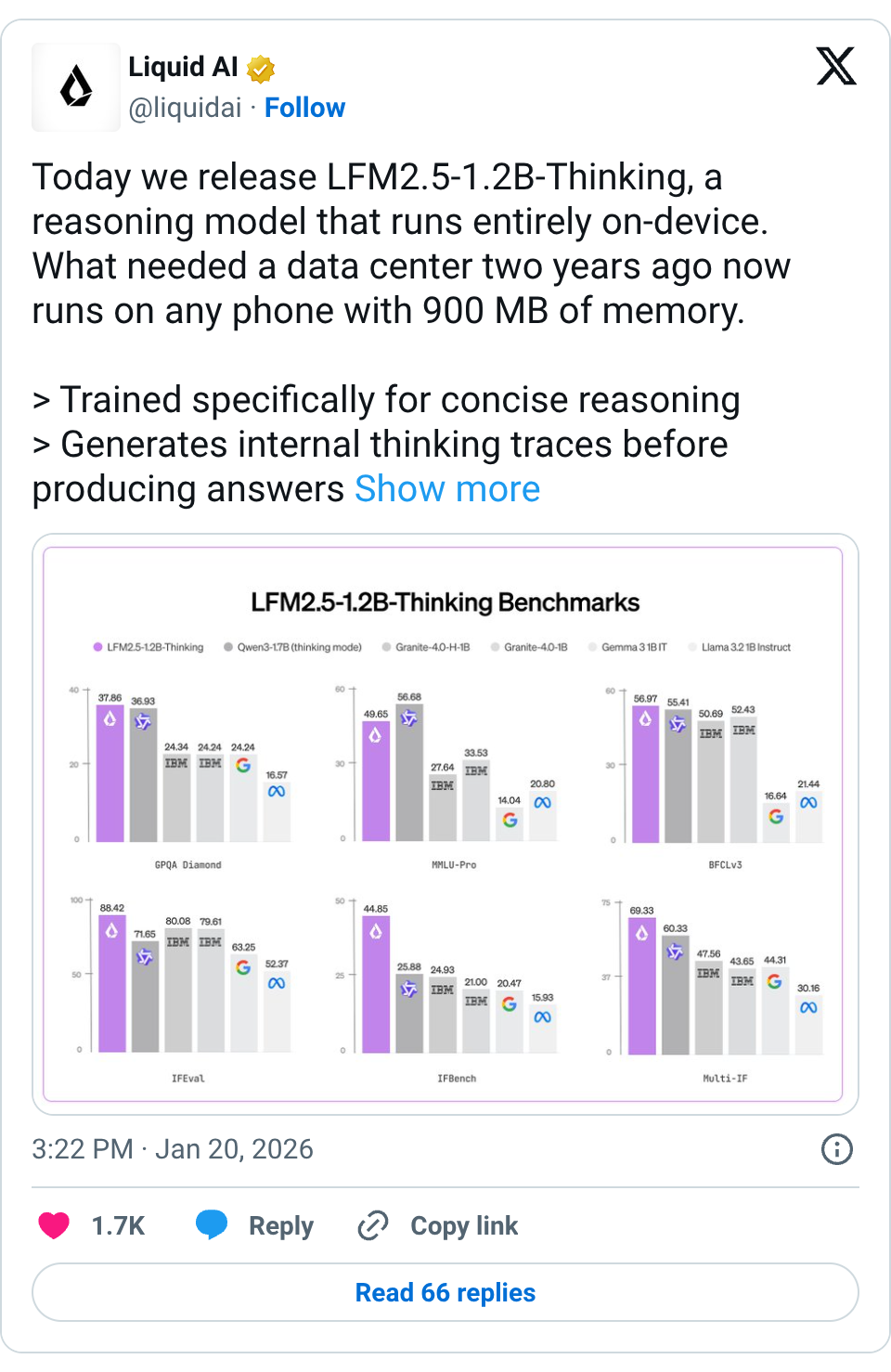
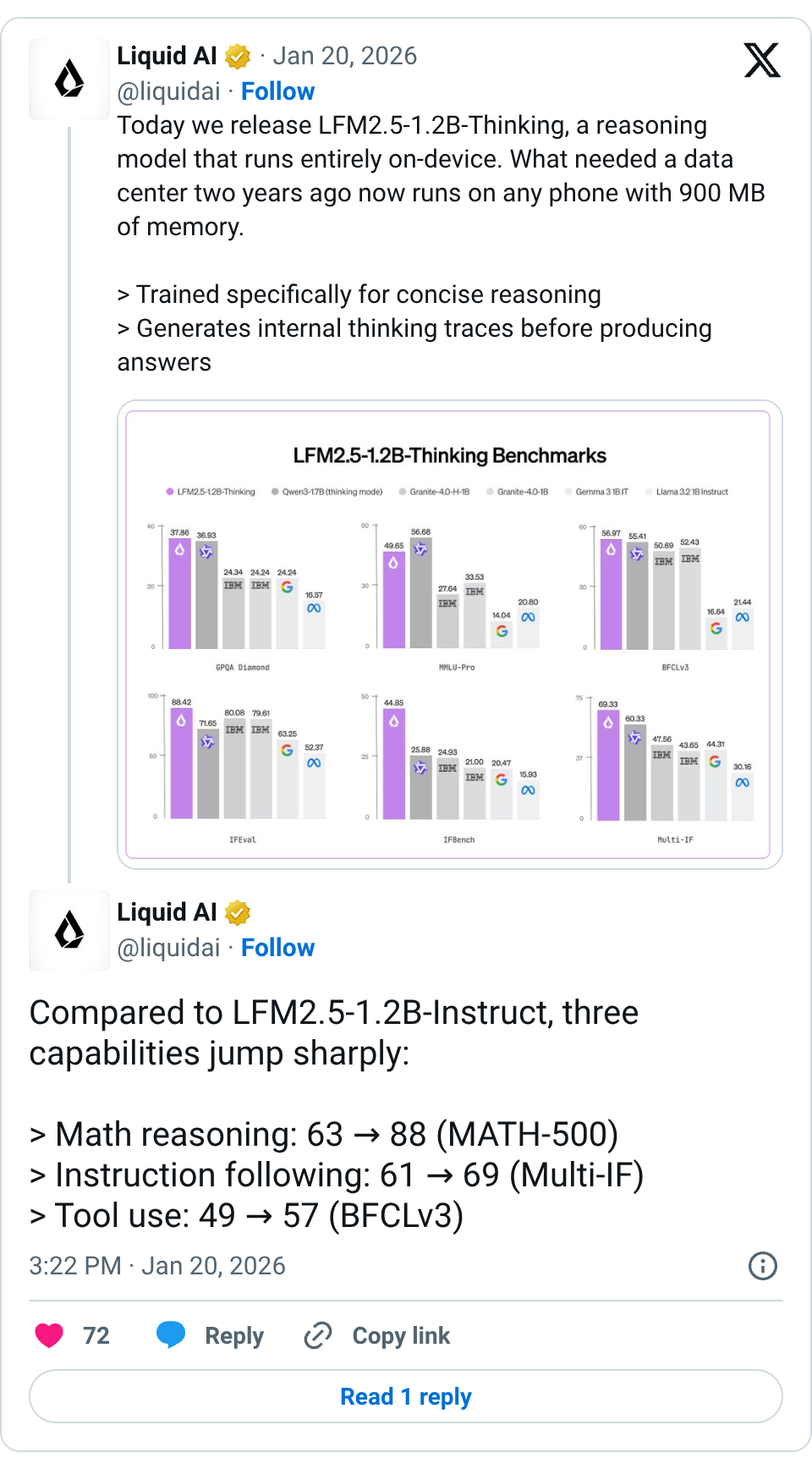
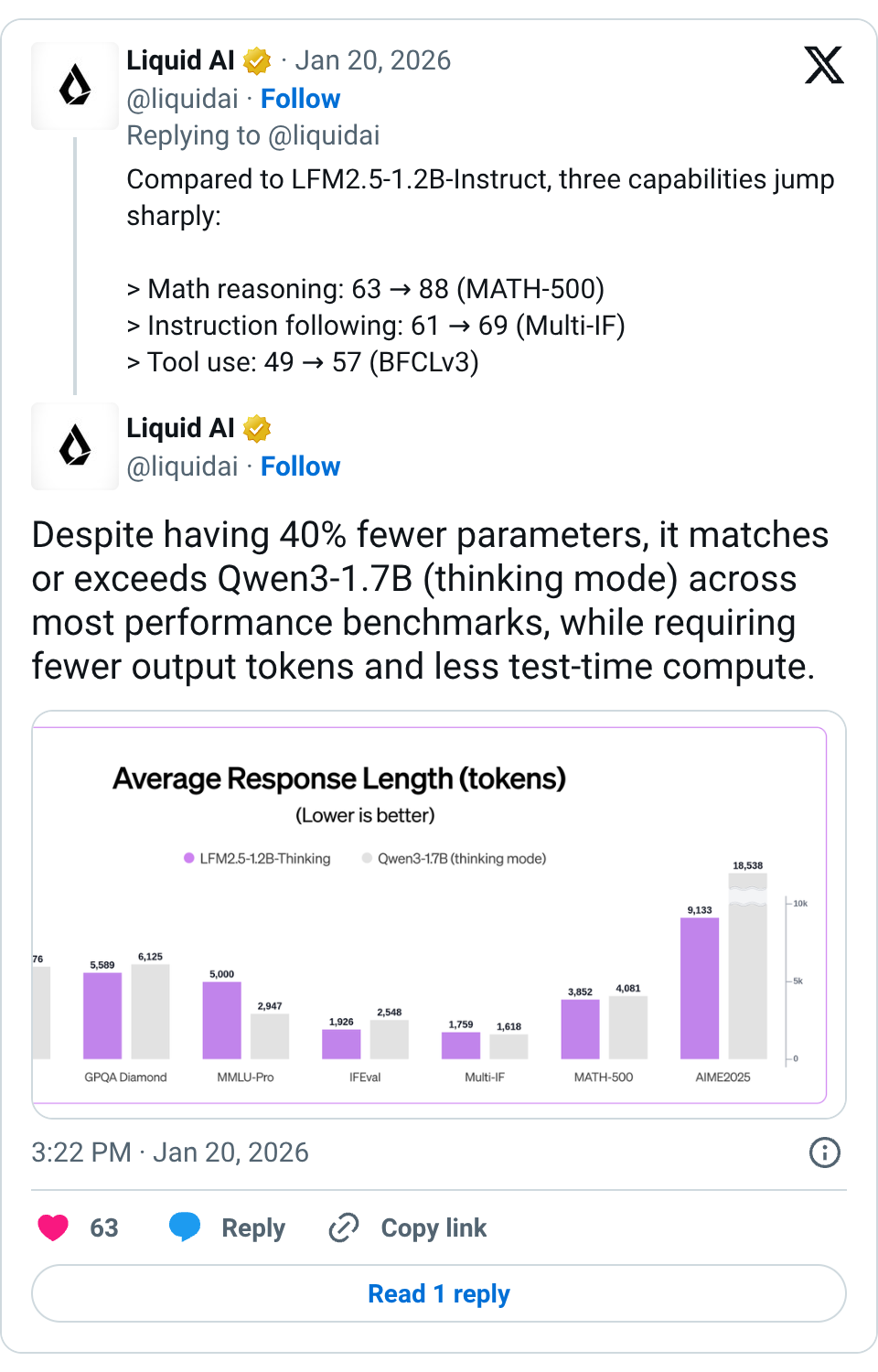
🧵 Today we release LFM2.5-1.2B-Thinking, a reasoning model that runs entirely on-device. What needed a data center two years ago now runs on any phone with 900 MB of memory. > Trained specifically for concise reasoning > Generates internal thinking traces before producing answers > Enables systematic problem-solving at edge-scale latency > Shines on tool use, math, and instruction following 🧵 Compared to LFM2.5-1.2B-Instruct, three capabilities jump sharply: > Math reasoning: 63 → 88 (MATH-500) > Instruction following: 61 → 69 (Multi-IF) > Tool use: 49 → 57 (BFCLv3) 🧵 Despite having 40% fewer parameters, it matches or exceeds Qwen3-1.7B (thinking mode) across most performance benchmarks, while requiring fewer output tokens and less test-time compute. 🧵 At inference time, the gap widens further. LFM2.5-1.2B-Thinking outperforms pure transformers (like Qwen3-1.7B) and hybrid architectures (like Granite-4.0-H-1B) in both speed and memory efficiency. 🧵 LFM2.5-1.2B-Thinking is available today with broad, day-one support across the on-device ecosystem. Hugging Face: https:// huggingface.co/LiquidAI/LFM2. 5-1.2B-Thinking … LEAP: https:// leap.liquid.ai/models?model=l fm2.5-1.2b-thinking … Liquid Playground: https:// playground.liquid.ai/login?callback Url=%2F … We are expanding the LFM2.5 platform with launch partners @Qualcomm Technologies, Inc., @ollama , FastFlowLM, and @cactuscompute , joining existing partners @AMD and @nexa_ai . These collaborations drive inference acceleration through optimized implementations across CPUs, NPUs, and GPUs, significantly broadening our support: > Nexa AI & FastFlowLM: Deliver optimized runtimes for Qualcomm Snapdragon® and AMD Ryzen™ NPUs. > Ollama & Cactus Compute: Streamline local and edge deployment workflows. 🧵 Start building with LFM today: > Fine-tune LFM2.5 with TRL ( https:// github.com/huggingface/trl) and Unsloth notebooks ( https:// github.com/unslothai/unsl oth …) > Day-zero support across the most popular inference frameworks, including llama.cpp, MLX, vLLM, and ONNX Runtime > All frameworks support both CPU and GPU acceleration across Apple, AMD, Qualcomm, and Nvidia hardware Read the full breakdown: https:// liquid.ai/blog/lfm2-5-1- 2b-thinking-on-device-reasoning-under-1gb …
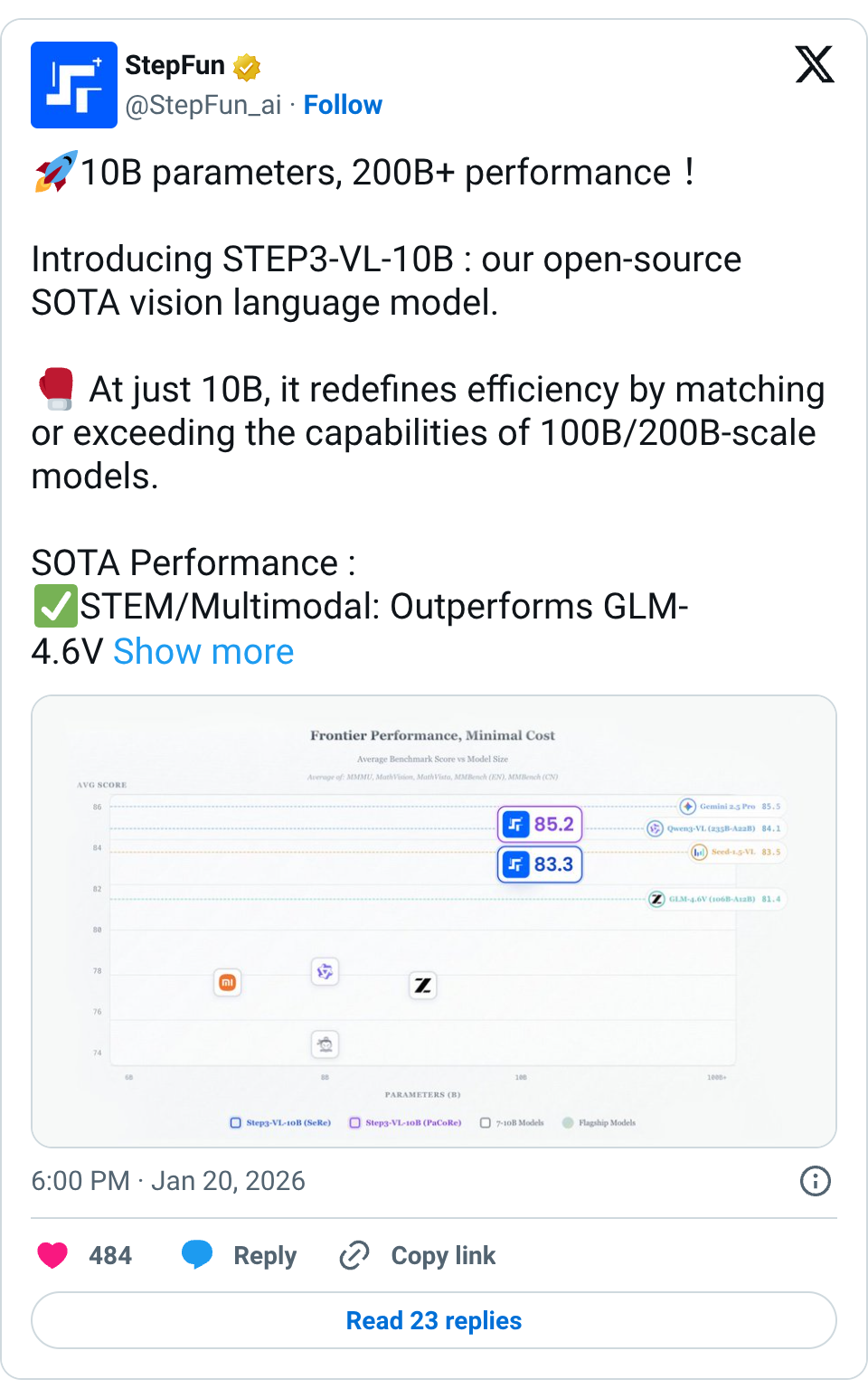
🧵 10B parameters, 200B+ performance! Introducing STEP3-VL-10B : our open-source SOTA vision language model. At just 10B, it redefines efficiency by matching or exceeding the capabilities of 100B/200B-scale models. SOTA Performance : STEM/Multimodal: Outperforms GLM-4.6V (106B-A12B) and Qwen3-VL (235B-A22B) on MMMU, MathVision, MathVerse,etc. Math: Near-perfect scores on AIME 24/25, achieving elite-level reasoning. 2D/3D Spatial Understanding: Beating same-scale models on BLINK/CVBench/OmniSpatial. Coding:Dominates LiveCodeBench in real-world dynamic programming. Key Breakthroughs: 1.2T token full-parameter pre-training. 1,400+ RL iterations for superior reasoning. Innovative PaCoRe tech for dynamic compute allocation. We prove that scale isn't everything. With high-quality targeted data and systematic post-training, a 10B model can go toe-to-toe with the industry's largest giants." Complex AI reasoning is now accessible for every device. Check out the Base & Thinking versions on HuggingFace now! Homepage: https:// stepfun-ai.github.io/Step3-VL-10B/ Paper: https:// arxiv.org/abs/2601.09668 HuggingFace: https:// huggingface.co/collections/st epfun-ai/step3-vl-10b … ModelScope: https:// modelscope.cn/collections/st epfun-ai/Step3-VL-10B … 🧵 Try it now: 🧵 ModelScope playground: https:// modelscope.cn/studios/stepfu n-ai/step3-vl-10b …
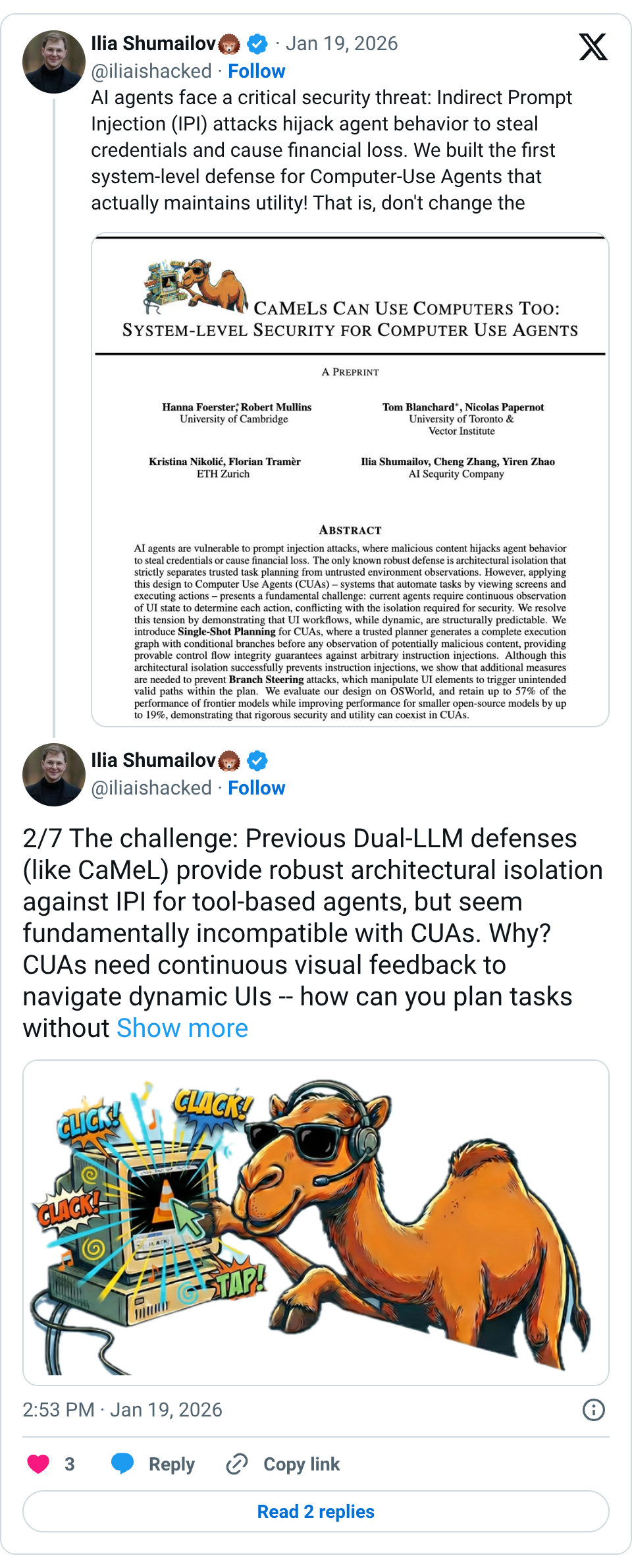
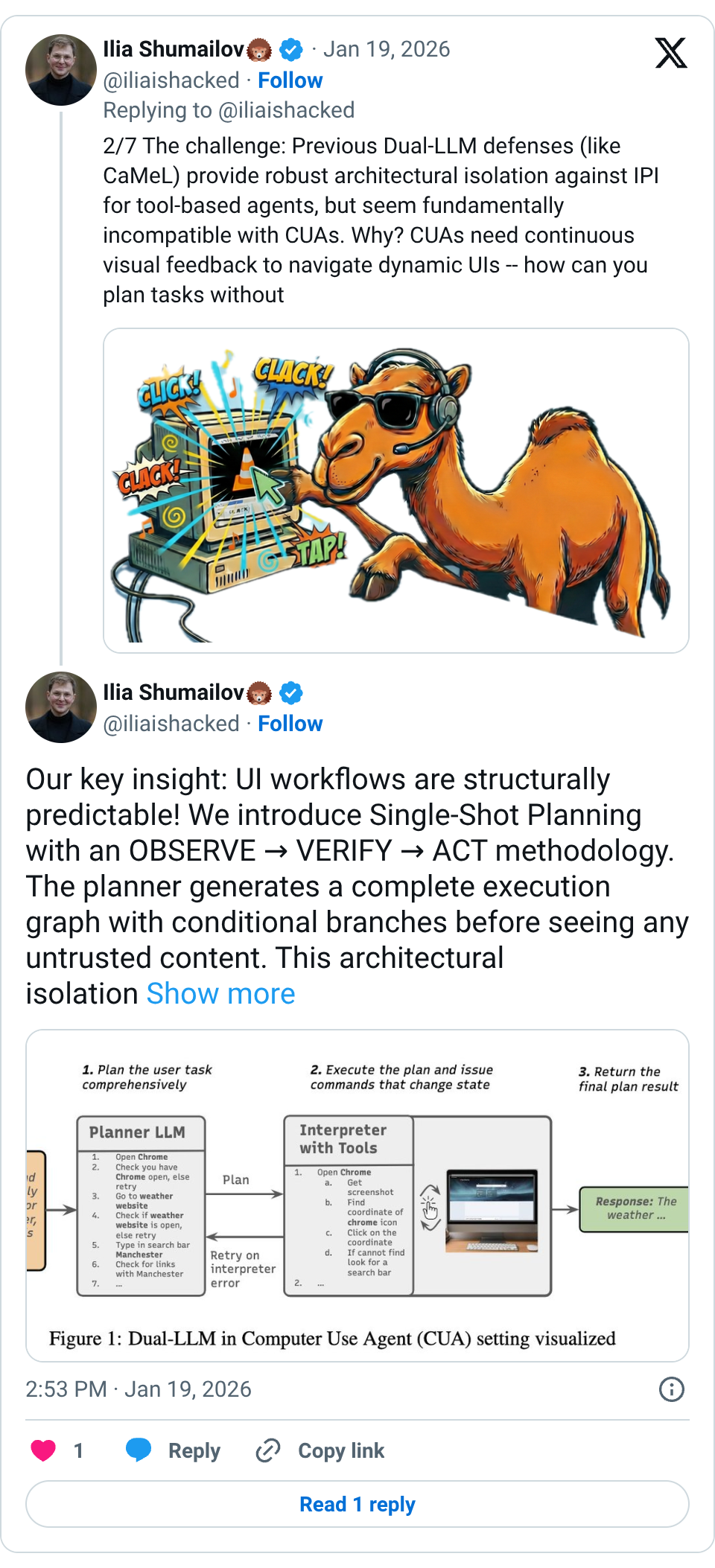
🧵 AI agents face a critical security threat: Indirect Prompt Injection (IPI) attacks hijack agent behavior to steal credentials and cause financial loss. We built the first system-level defense for Computer-Use Agents that actually maintains utility! That is, don't change the model, change the system around it to guarantee control flow integrity! https:// arxiv.org/pdf/2601.09923 🧵 2/7 The challenge: Previous Dual-LLM defenses (like CaMeL) provide robust architectural isolation against IPI for tool-based agents, but seem fundamentally incompatible with CUAs. Why? CUAs need continuous visual feedback to navigate dynamic UIs -- how can you plan tasks without ever seeing the screen content? Turns out you can ?! 🧵 Our key insight: UI workflows are structurally predictable! We introduce Single-Shot Planning with an OBSERVE → VERIFY → ACT methodology. The planner generates a complete execution graph with conditional branches before seeing any untrusted content. This architectural isolation provides provable Control Flow Integrity guarantees! 🧵 The results surprised us: Single-shot planning achieves ~57% performance retention for frontier models and up to +19% improvement for smaller models on OSWorld. Performance is driven more by the planner's reasoning than the CUA's capabilities -- security scales favorably as foundation models improve! Yes, for the first time in our field better models unlock security! 🧵 But there's a catch: While we prevent arbitrary instruction injection, data-flow remains vulnerable to what we call Branch Steering attacks. Attackers can't inject new actions, but they can manipulate visual cues (fake cookie popups in ads, pixel perturbations) to force execution down attacker-chosen valid branches. Its similar to ROP attacks. 🧵 We added verification layers (cross-checking perception outputs with DOM structure and independent VLMs) to catch manipulated data. But even these defenses can be evaded—we demonstrate branch steering attacks—including fake cookie popups and gradient-based pixel perturbations—that can still evade these defenses by exploiting the data flow within valid plan branches. 🧵 TL;DR: System-centric security IS compatible with CUAs! Many seemingly data-dependent tasks (navigating dynamic UIs) can be reduced to data-independent ones through comprehensive planning. As reasoning models improve, secure single-shot planning becomes increasingly practical -- proving rigorous security and utility can coexist for real-world CUA deployment. Work with @hfoerster01 , Tom Blanchard, @NKristina01_ , Robert Mullins, @NicolasPapernot , @florian_tramer , @iliaishacked , @aaronzhao123 , Cheng Zhang, and @aisequrity Link: https:// arxiv.org/pdf/2601.09923

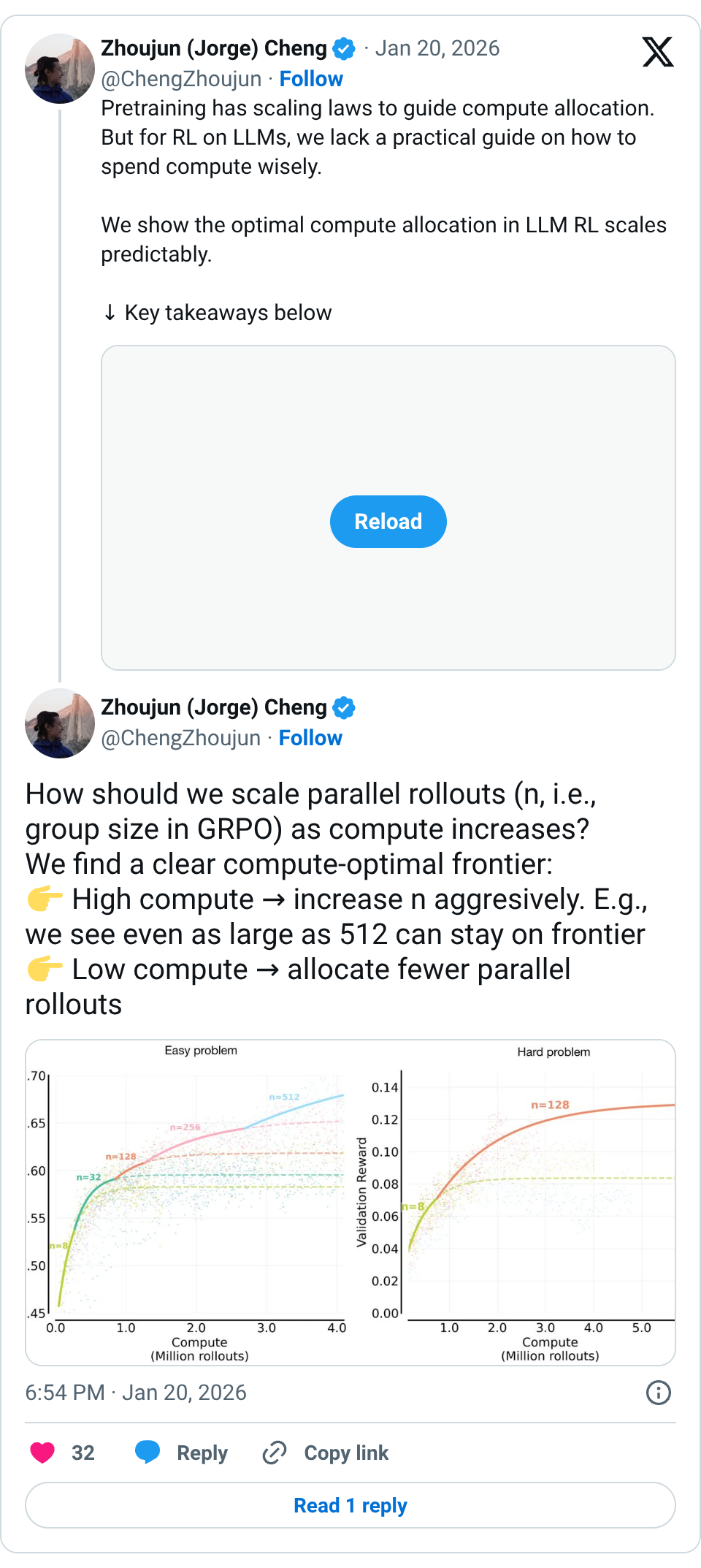
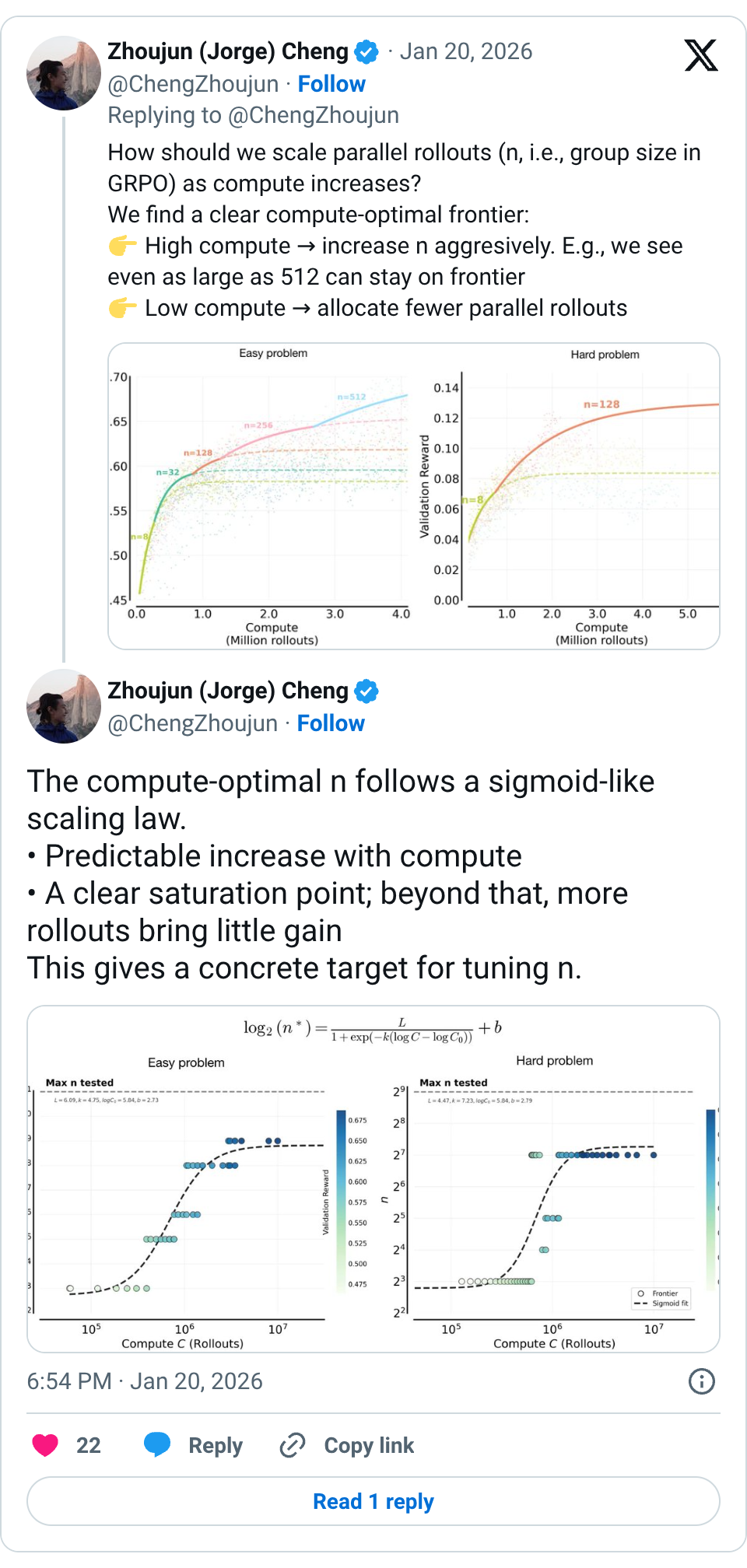
🧵 Pretraining has scaling laws to guide compute allocation. But for RL on LLMs, we lack a practical guide on how to spend compute wisely. We show the optimal compute allocation in LLM RL scales predictably. ↓ Key takeaways below 🧵 How should we scale parallel rollouts (n, i.e., group size in GRPO) as compute increases? We find a clear compute-optimal frontier: High compute → increase n aggresively. E.g., we see even as large as 512 can stay on frontier Low compute → allocate fewer parallel rollouts 🧵 The compute-optimal n follows a sigmoid-like scaling law. • Predictable increase with compute • A clear saturation point; beyond that, more rollouts bring little gain This gives a concrete target for tuning n. 🧵 The same n-scaling trend holds for both easy and hard problems, but for very different reasons. • Easy: larger n prioritizes sharpening on solvable problems (↑ worst@k) • Hard: larger n expands coverage of unsolvable problems (↑ best@k) 🧵 In practice, batch size is often capped due to hardware constraint. With total batch B: More compute → more rollouts per problem (n) → fewer problems per batch 🧵 What actually dictates this scaling curve of n? We study several factors that affect where saturation point of n happens. 🧵 Base model: the scaling n for high compute findings generalize across different base models, though the saturation point varies. 🧵 Problem set size: smaller dataset size would shfit to smaller saturation point of n due to early overfitting. 🧵 Problem distribution: on mixed distributions, the scaling n trend holds, while the optimal n is heavily influenced by the specific metric one wishes to optimize (due to interference between easy and hard prompts). 🧵 Beyond in-domain validation rewards, scaling n also improves downstream AIME scores, suggesting clear practical benefits. 🧵 Huge thanks to the amazing collaborators. Co-led with @YutaoXie12174 , @QuYuxiao , @setlur_amrith ; thanks to @Ber18791531 , @varad0309 , tongtongliang, @fengyao1909 , @tw_killian , @aviral_kumar2 , and others. Thanks @aviral_kumar2 again for being such a kind, sharp, and principled advisor, and for the guidance and encouragement to pursue real science. 🧵 Blog link … https://com pute-optimal-rl-llm-scaling.github.io 🧵 last thread to the physics of LLM: I really like the concept of physics of LLM and feel lucky to work on similar questions. https:// physics.allen-zhu.com/part-1 @ZeyuanAllenZhu 🧵 Thanks Nathan! 🧵 Thanks Junli. May we build sth huge (or tiny). 🧵 thanks!
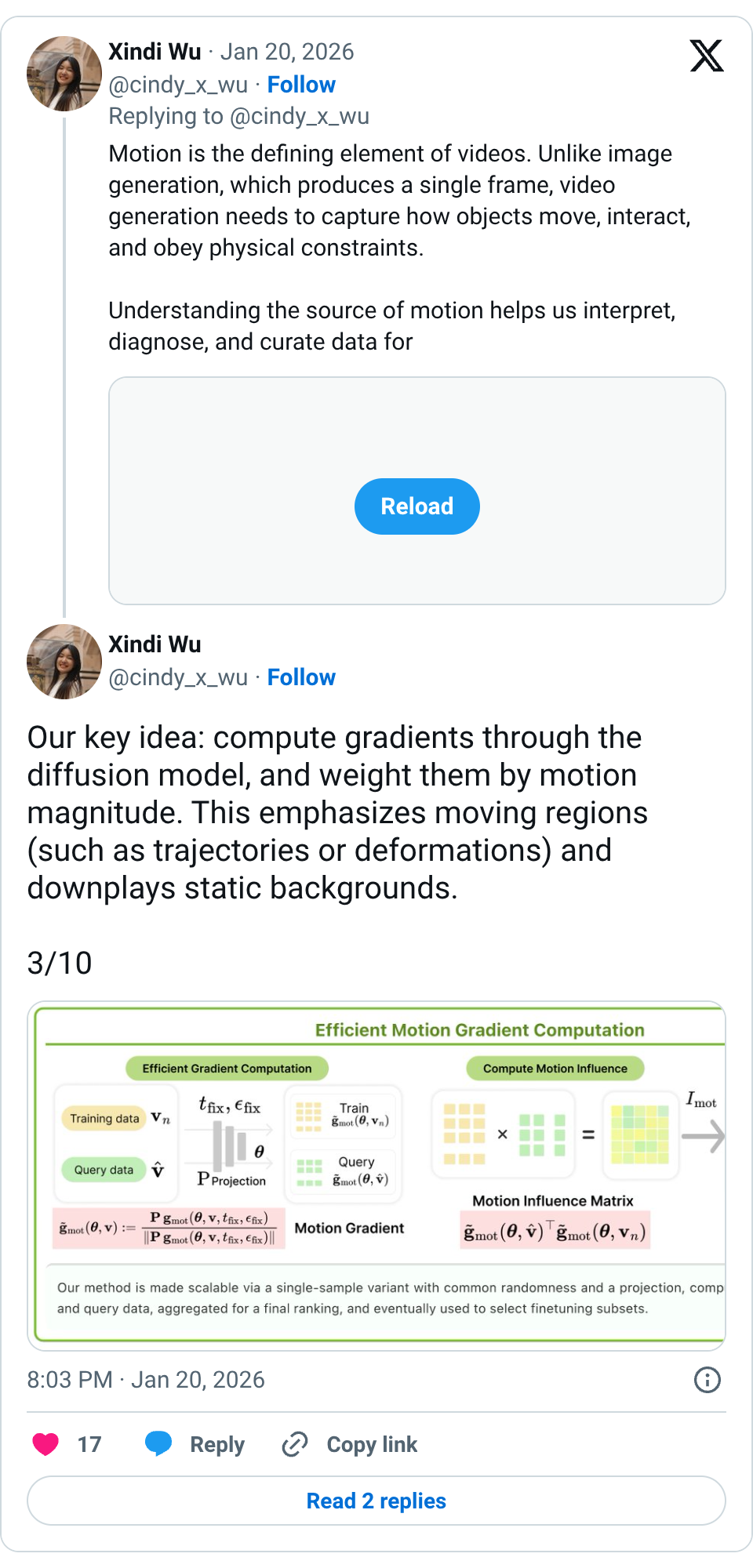
🧵 New #NVIDIA Paper We introduce Motive, a motion-centric, gradient-based data attribution method that traces which training videos help or hurt video generation. By isolating temporal dynamics from static appearance, Motive identifies which training videos shape motion in video generation. https:// research.nvidia.com/labs/sil/proje cts/MOTIVE/ … 1/10 🧵 Motion is the defining element of videos. Unlike image generation, which produces a single frame, video generation needs to capture how objects move, interact, and obey physical constraints. Understanding the source of motion helps us interpret, diagnose, and curate data for better video generation models. 2/10 🧵 Our key idea: compute gradients through the diffusion model, and weight them by motion magnitude. This emphasizes moving regions (such as trajectories or deformations) and downplays static backgrounds. 3/10 🧵 We extract motion masks using AllTracker and compute motion-weighted influence scores. The result is a ranking of which training clips most strongly affect a model’s temporal behavior. 4/10 🧵 Using these influence scores, we select only the most motion-relevant data for fine-tuning. With only 10% of the data, we surpass full-dataset results. Motive improves dynamic degree and motion smoothness on VBench while preserving visual and semantic quality. 5/10 🧵 In human studies, videos generated with Motive-selected data were preferred 74.1% of the time over the base model and 53.1% over full fine-tuning. Participants found the motion smoother and more physically consistent. 6/10 🧵 Motive reveals that video models share influential training data across related motion types. High-overlap pairs like bounce-float suggest shared underlying dynamics, while low-overlap pairs like free fall and stretch indicate distinct learning preferences. These patterns hold consistently across datasets, suggesting certain motion types share transferable training signals. 7/10 🧵 Motive suggests a new axis for scaling video generation data: not how much data we use, but which motion patterns we train on. This motion-level attribution helps us understand how video diffusion models internalize motion dynamics. If we can trace which experiences teach which 🧵 Motive is inspired by a growing body of work on motion, world modeling, and data attribution, from large-scale video diffusion (Wan, @Alibaba_Wan , Veo, Cosmos), to influence-based analysis, such as TRAK ( @kris_georgiev1 , @andrew_ilyas ), systematic video evaluation efforts such as VBench ( @liuziwei7 ), dense point tracking (AllTracker, @AdamWHarley ), and many others. We’re excited to build on these ideas and push data-centric tools toward understanding how motion is learned. 9/10 🧵 Huge thanks to my amazing coauthors @paschalidoud_1 @JunGao33210520 Antonio Torralba @lealtaixe @orussakovsky @FidlerSanja @jonLorraine9 , I learned so much working with them! Check out more cool research at: https:// research.nvidia.com/labs/sil/ @NVIDIAAI @PrincetonCS @MIT_CSAIL @UofTCompSci @VectorInst 10/10 🧵 Congrats Xindi!! 🧵 Thank you Amir!!!
🧵 1/5 I’ve worried for a while that “AI agents” are basically turnkey privacy attacks waiting to happen. I tested it on the Anthropic Interviewer transcript release. It worked way too well. Paper: https:// arxiv.org/abs/2601.05918 🧵 2/5 Anthropic released 1,250 AI-led interviews (125 w/ scientists) with identifiers redacted. My goal was to measure residual re-identification risk. 🧵 3/5 Method (high level): (1) spot interviews likely describing a specific published work; (2) use a web-augmented LLM to search + rank candidate publications with confidence estimates. 🧵 4/5 Results: 24/125 scientist transcripts looked publication-related. For 6/24 I recovered the exact publication and manually verified the match. Some were theses/dissertations → single-author → uniquely identifying. 🧵 5/5 It’s not about obscure exploits—it’s about lowering the barrier: re-ID becomes a promptable workflow with common tools. We need to rethink safe data release in the age of agentic LLMs (stress tests, safer formats, defenses against LLM-enabled re-ID)


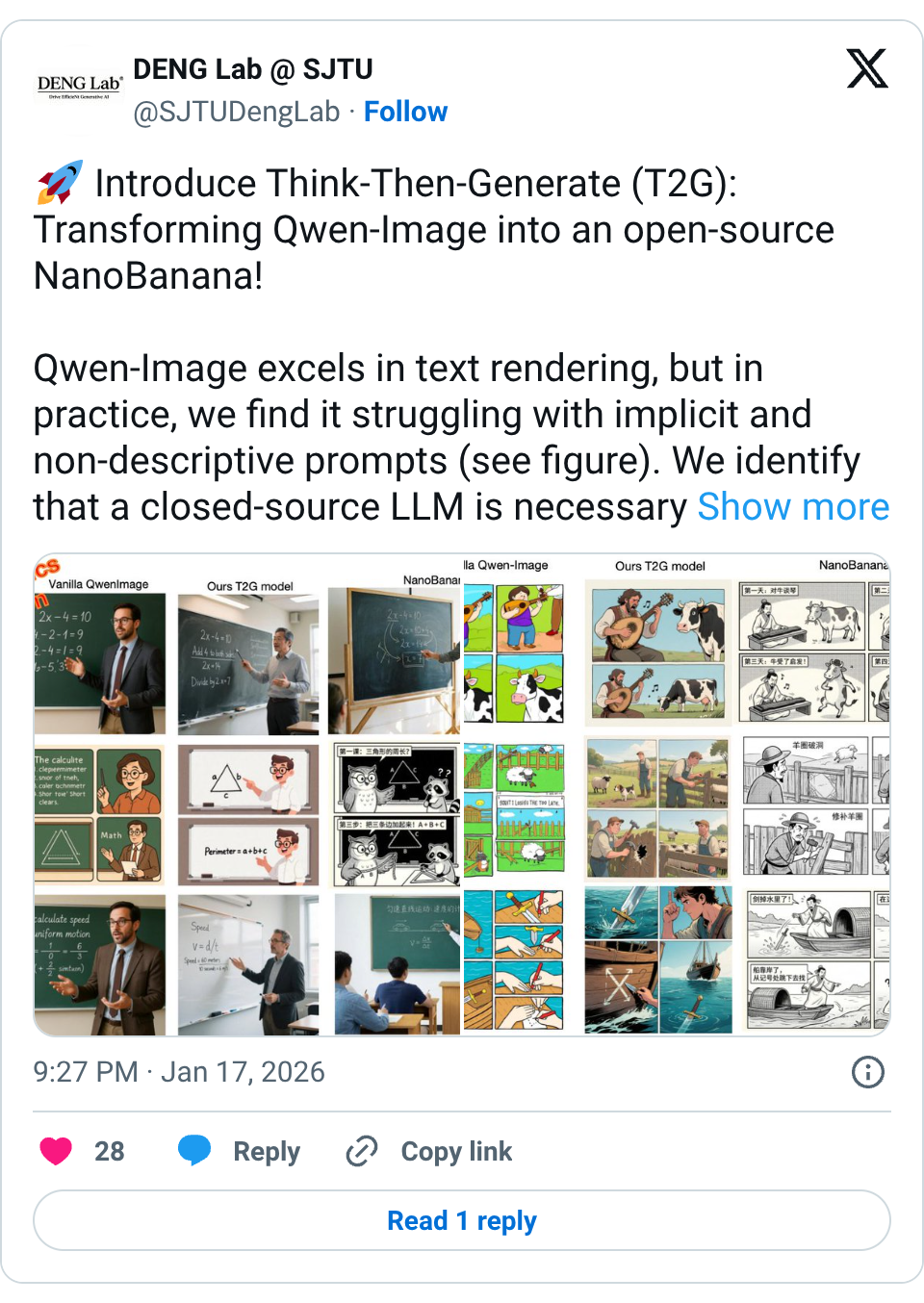
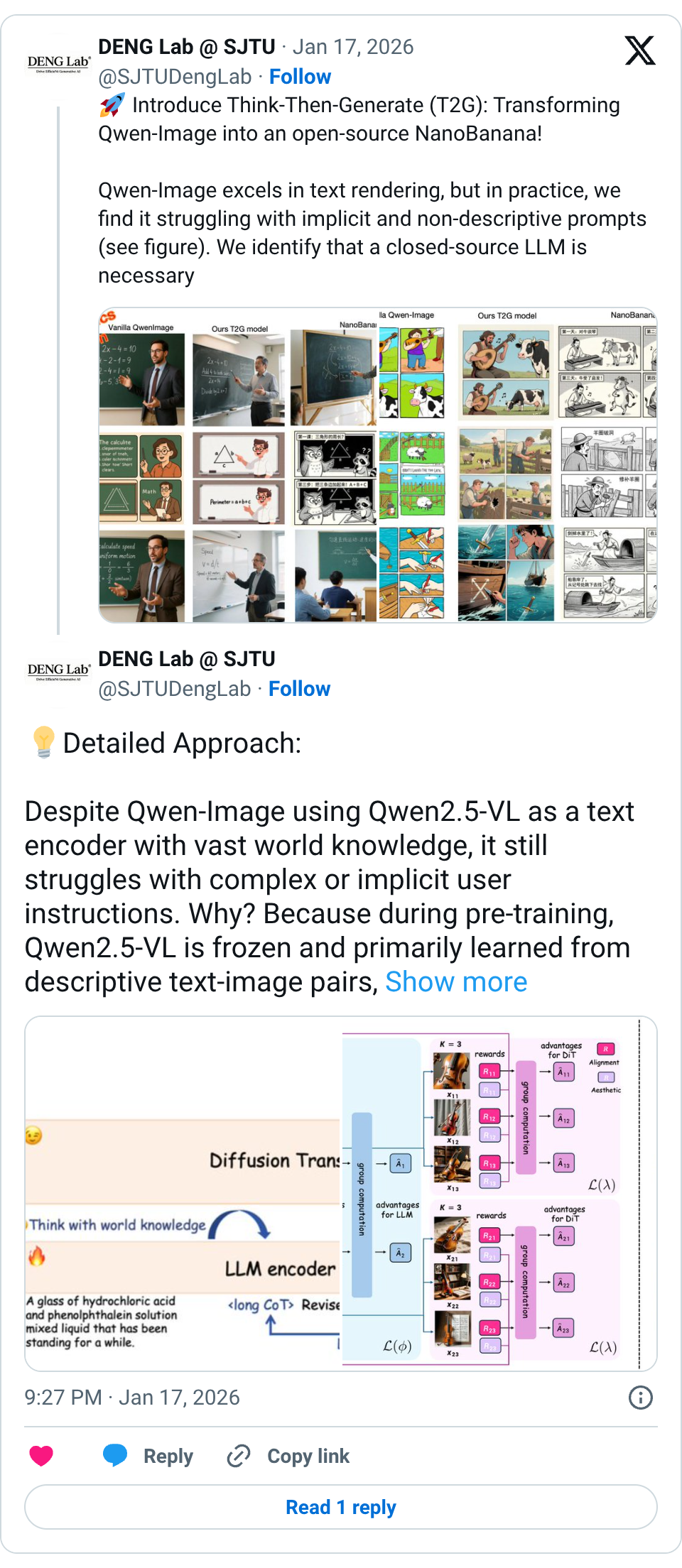
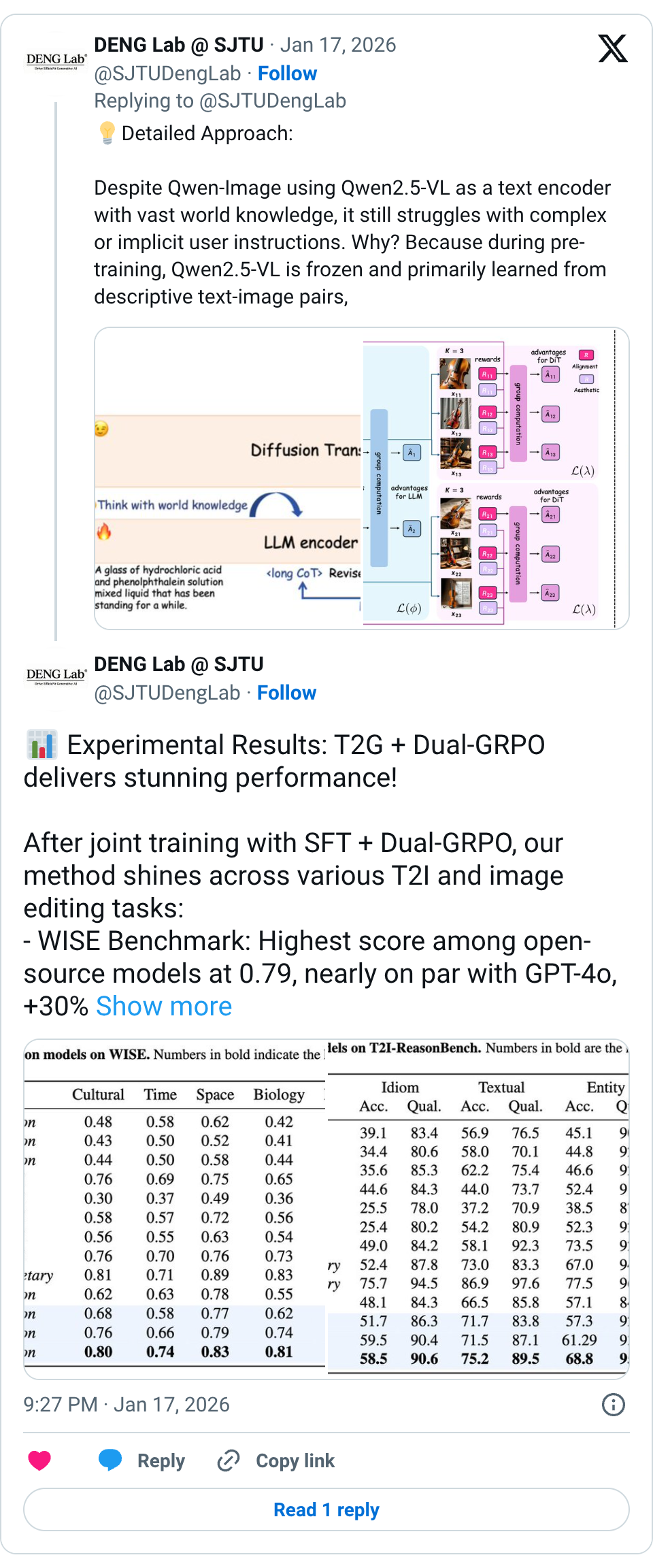
🧵 Introduce Think-Then-Generate (T2G): Transforming Qwen-Image into an open-source NanoBanana! Qwen-Image excels in text rendering, but in practice, we find it struggling with implicit and non-descriptive prompts (see figure). We identify that a closed-source LLM is necessary to rewrite prompts descriptively for the diffusion transformer (DiT) renderer. However, the disconnect between the LLM and DiT can lead to imperfections. Our solution: T2G—Think First, Generate Second! T2G overcomes this by empowering the text encoder in Qwen-Image itself (i.e., Qwen2.5-VL) to think first, then generate with DiT, and introducing a multimodal GRPO (Dual-GRPO) strategy to enhance seamless, self-driven reasoning in Qwen2.5-VL. Check out some results first: - Idiom Comics: Input “A multi-panel comic showing ‘playing the lute to a cow’” -> Not just images of cows and instruments, but a dynamic, narrative-driven comic with accurate evolution of the idiom’s context. - Math & Physics Teaching Example: Input “A math teacher explaining the equation 2x − 4 = 10 on the blackboard.” -> Not random elements, but a fully structured blackboard with clear steps and a teacher scene, accurately capturing the teaching process. Paper: https:// arxiv.org/abs/2601.10332 Github: https:// github.com/SJTU-DENG-Lab/ Think-Then-Generate … 🧵 Detailed Approach: Despite Qwen-Image using Qwen2.5-VL as a text encoder with vast world knowledge, it still struggles with complex or implicit user instructions. Why? Because during pre-training, Qwen2.5-VL is frozen and primarily learned from descriptive text-image pairs, focusing on surface-level visual mappings instead of truly understanding and reasoning about user intent. We overcome this by: Activates the Thinking: Fine-tune Qwen2.5-VL with a lightweight SFT process. This activates the thinking pattern to first perform CoT reasoning of user prompts and then generate an optimized prompt before DiT rendering. Collaborative Multimodal Reinforcement: Use Dual-GRPO strategy, where Qwen2.5-VL and DiT are updated simultaneously: - Qwen2.5-VL adjusts reasoning based on image-grounded rewards focusing on image consistency with user intent. - DiT is trained based on image quality rewards to enhance the rendering capabilities of the optimized prompt and the evolving text encoding space. Bridge the Gap: The optimized prompt links Qwen2.5-VL's reasoning and DiT's rendering, ensuring true intent understanding and world knowledge integration. 🧵 Experimental Results: T2G + Dual-GRPO delivers stunning performance! After joint training with SFT + Dual-GRPO, our method shines across various T2I and image editing tasks: - WISE Benchmark: Highest score among open-source models at 0.79, nearly on par with GPT-4o, +30% improvement over original Qwen-Image. - T2I-ReasonBench: Achieved 92.2 overall score, outperforming closed-source models like Gemini-2.0. - RISEBench & UniREditBench: Significant performance boost in editing tasks with just 5000 samples post-RL training. 🧵 Connection with GLM-Image: The recently released GLM-Image adopts a similar approach—maximizing the semantic capture of the LLM text encoder, using it as the "brain" to understand semantics, while the DiT focuses on a faithful visual renderer. Our method directly reasons over textual space to interpret complex user instructions, while GLM focuses on capturing semantics within the visual token space. Here is our gallery to compare results from different models: https:// sjtu-deng-lab.github.io/Think-Then-Gen erate …. Feel free to see more comparisons.
🧵 Any static 3D assets 4D dynamic worlds. Introducing CHORD, a universal framework for generating scene-level 4D dynamic motion from any static 3D inputs. It generalizes surprisingly well across a wide range of objects and can even be used to learn robotics manipulation policy ! Project page: https:// yanzhelyu.github.io/chord. Dive deeper in a : 1/n 🧵 Generative AI has seen remarkable success in generating static 3D shapes. Yet, building a comprehensive 4D World Model requires a crucial missing piece: realistic dynamics. CHORD presents a universal framework to bridge this gap: Input: Static 3D objects (zero dynamic annotations). Output: Plausible 4D object motion & coherent 4D scenes. No rigs or skeletons required. : 2/n 🧵 Crucially, our pipeline operates without any category-specific priors or dynamic structural annotations. This flexibility allows CHORD to generate a diverse range of complex object interactions. Watch the example below: A generated 4D world showing a child launching a brick with a seesaw. : 3/n 🧵 Our pipeline generates spatially consistent 4D scenes, meaning they can be viewed from any angle. You can navigate these generated worlds using standard graphics renderers, or step inside with a VR headset or AR glasses. Explore the interactive viewer yourself: https:// yanzhelyu.github.io/chord/#viewer 4/n 🧵 By leveraging explicit 3D representations, CHORD generates motion that is physically grounded, not just visually plausible. This ensures physical consistency, enabling direct transfer to robotic systems. View more examples here: https:// yanzhelyu.github.io/chord/#robot 5/n 🧵 Explicit 4D representations = Perfect memory for 4D world generation. This allows us to generate coherent, minute-long 4D worlds without the physics breaking down. Witness a full minute-long sequence: 1. Move plate to microwave 2. Wait for heating 3. Retrieve plate 6/n 🧵 How does it work? We employ a robust distillation strategy to learn dynamic motion patterns from large-scale video generative models. Read more in our paper: https:// yanzhelyu.github.io/chord/static/f iles/chord.pdf … 7/n 🧵 With CHORD, the creative possibilities are endless. Users can generate a limitless variety of fun 4D worlds. Watch this: A generated 4D scene of Captain America taking a break to pet a dog! 8/n 🧵 A cat jumping onto a cushion. Notice the realistic physical interaction: Watch how the cushion deforms and reacts to the cat's weight as it lands. Our pipeline generates these subtle contact dynamics automatically, without complex physical equations defined in simulators! 9/n 🧵 Even the Dark Side has to obey the laws of physics! Watch a 4D scene of Darth Vader pushing down on a desk lamp. Notice the articulation: the lamp folds and compresses naturally under the force of the hand. 10/n 🧵 Ezio is playing with his eagle. This 4D scene demonstrates our model's ability to generate human-animal interactions. Notice the natural timing and coordination between the two figures. 11/n 🧵 This thread only scratches the surface. We have a massive gallery of generated 4D results, comparisons, and interactive demos on our website. Explore the full gallery: https:// yanzhelyu.github.io/chord/#app 12/n 🧵 Project page: https:// yanzhelyu.github.io/chord Paper: https:// arxiv.org/abs/2601.04194 13/n 🧵 This project is led by our talented summer intern Yanzhe Lyu ( @yanzhelyu01 ), in collaboration with @KDharmarajan123 , @zhang_yunzhi , @HadiZayer , @elliottszwu , and @jiajunwu_cs . Yanzhe is applying for PhD programs this cycle. He is truly exceptional, and any top program would be fortunate to have him. Don’t miss out! 14/14 🧵 great work! would love to see some results on SMPL / g1